
Forum OpenACS Q&A: Issue with reachable method in 5.10.1 dynamic clustering setup
Posted by
Jonathan Kelley
on 11/16/23 02:57 PM
Posted by
Gustaf Neumann
on 11/19/23 06:53 PM
Posted by
Jonathan Kelley
on 11/21/23 06:39 PM
Posted by
Gustaf Neumann
on 11/27/23 07:37 PM
Posted by
Jonathan Kelley
on 11/27/23 09:17 PM
Posted by
Gustaf Neumann
on 11/28/23 04:59 PM
Posted by
Jonathan Kelley
on 11/29/23 02:33 PM
Posted by
Gustaf Neumann
on 11/30/23 10:30 AM
Posted by
Gustaf Neumann
on 11/30/23 06:33 PM
Posted by
Jonathan Kelley
on 11/30/23 06:44 PM
Posted by
Jonathan Kelley
on 11/30/23 06:47 PM
Posted by
Gustaf Neumann
on 12/05/23 11:05 AM
Posted by
Jonathan Kelley
on 12/05/23 02:47 PM
Posted by
Gustaf Neumann
on 12/05/23 03:46 PM
The recent change was just about the display on the cluster admin page. The detection of not-reachable servers is there since a while.
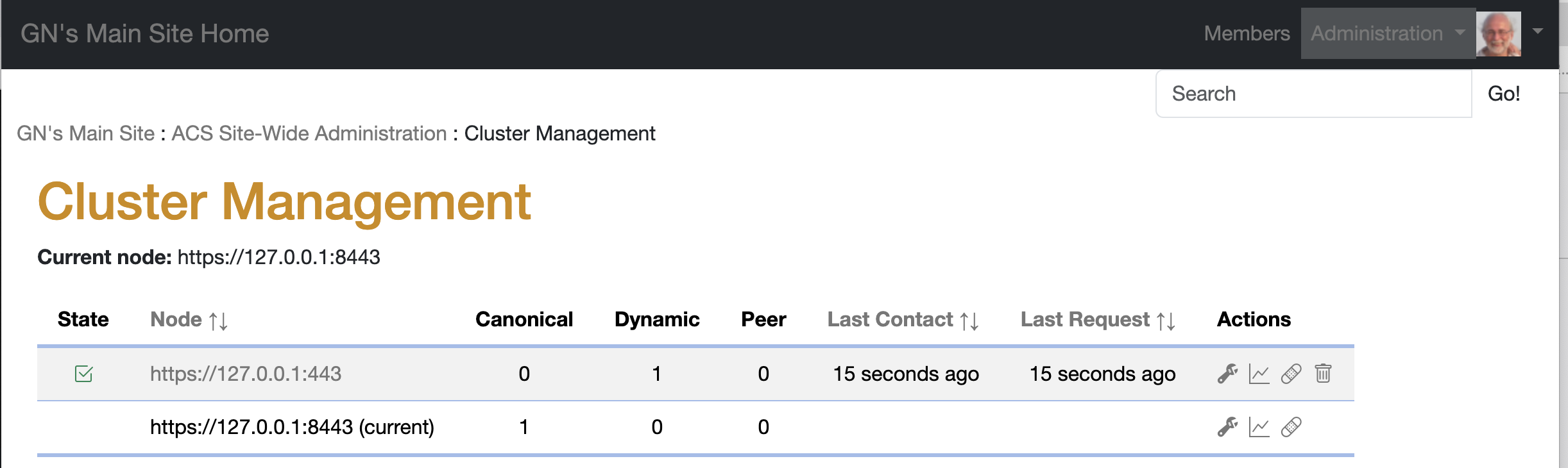
Here is a screenshot with the canonical server and an active node
If you experience an error, please submit a bug report.
Here is a screenshot with the canonical server and an active node
... and a screenshot with the canonical server and an inactive node

It looks like it would require manual cleanup using the status page as a guide for the level of inactivity?What makes you think this?
If you experience an error, please submit a bug report.
-g
Posted by
Jonathan Kelley
on 12/05/23 03:58 PM
Posted by
Gustaf Neumann
on 12/05/23 04:20 PM
Posted by
Jonathan Kelley
on 12/05/23 07:55 PM
Posted by
Gustaf Neumann
on 12/06/23 11:56 AM
Posted by
Jonathan Kelley
on 12/07/23 12:28 AM
Posted by
Gustaf Neumann
on 12/07/23 01:34 PM
Posted by
Jonathan Kelley
on 12/07/23 04:29 PM
Posted by
Gustaf Neumann
on 12/18/23 10:52 AM