
Overview
The schema for the entities that actually collect, store and retrieve Assessment data parallels the hierarchical structure of the Metadata Data Model. In the antecedent "complex survey" and "questionnaire" systems, this schema was simple two-level structure:
- survey_responses which capture information about which survey was completed, by whom, when, etc
- survey_question_responses which capture the actual user data in a "long skinny table" mechanism
This suffices for one-shot surveys but doesn't support the fine granularity of user-action tracking, "save&resume" capabilities, and other requirements identified for the enhanced Assessment package. Consequently, we use a more extended hierarchy:
- Assessment Session which captures information about which Assessment, which Subject, when, etc
- Section Data which holds information about the status of each Section
- Item Data which holds the actual data extracted from the Assessment's html forms; this is the "long skinny table"
To support user modification of submitted data (of which "store&resume" is a special case), we base all these entities in the CR. In fact, we use both cr_items and cr_revisions in our schema, since for any given user's Assessment submission, there indeed is a "final" or "live" version. In contrast, recall that for any Assessment itself, different authors may be using different versions of the Assessment. While this situation may be unusual, the fact that it must be supported means that the semantics of cr_items don't fit the Assessment itself. They do fit the semantics of a given user's Assessment "session" however.
We distinguish here between "subjects" which are users whose information is the primary source of the Assessment's responses, and "users" which are real OpenACS users who can log into the system. Subjects may be completing the Assessment themselves or may have completed some paper form that is being transcribed by staff people who are users. We thus account for both the "real" and one or more "proxy" respondents via this mechanism. Note that subjects may or may not be OpenACS users who can log into the system running Assessment. Thus subject_id will be a foreign key to persons not users. If the responding user is completing the assessment for herself, the staff_id will be identical to the subject_id. But if the user completing the assessment is doing it by proxy for the "real" subject, then the staff_id will be hers while the subject_id will belong to the "real" subject.
We've simplified this subsection of Assessment considerably from earlier versions, and here is how and why:
- Annotations: We previously had a separate table to capture any type of ad hoc explanations/descriptions/etc that a user would need to attach to a given data element (either an item or section). Instead, we will use the OpenACS General Comments package, which is based on the CR and thus can support multiple comments attached to a given revision of a data element. The integration between Assessment and GC thus will need to be at the UI level, not the data model level. Using GC will support post-test "discussions" between student and teacher, for example, about individual items, sections or sessions.
-
Scoring-grading: This has been a rather
controversial area because of the wide range of needs for derived
calculations/evaluations that different applications need to
perform on the raw submitted data. In many cases, no calculations
are needed at all; only frequency reports ("74% of responders
chose this option") are needed. In other cases, a given item
response may itself have some measure of "correctness"
("Your answer was 35% right.") or a section may be the
relevant scope of scoring ("You got six of ten items correct
-- 60%.). At the other extreme, complex scoring algorithms may be
defined to include multiple scales consisting of arbitrary
combinations of items among different sections or even consisting
of arithmetic means of already calculated scale scores.
Because of this variability as well as the recognition that Assessment should be primarily a data collection package, we've decided to abstract all scoring-grading functions to one or more additional packages. A grading package (evaluation) is under development now by part of our group, but no documentation is yet available about it. How such client packages will interface with Assessment has not yet been worked out, but this is a crucial issue to work through. Presumably something to do with service contracts. Such a package will need to interact both with Assessment metadata (to define what items are to be "scored" and how they are to be scored -- and with Assessment collected data (to do the actual calculations and mappings-to-grades.
-
Signatures: The purpose of this is to provide
identification and nonreputability during data submission. An
assessment should optionally be configurable to require a
pass-phrase from the user at the individual item level, the section
level, or the session level. This pass-phrase would be used to
generate a hash of the data that, along with the system-generated
timestamp when the data return to the server, would uniquely mark
the data and prevent subsequent revisions. For most simple
applications of Assessment, all this is overkill. But for
certification exams (for instance) or for clinical data or
financial applications, this kind of auditing is essential.
We previously used a separate table for this since probably most assessments won't use this (at least, that is the opinion of most of the educational folks here). However, since we're generating separate revisions of each of these collected data types, we decided it would be far simpler and more appropriate to include the signed_data field directly in the as_item_data table. Note that for complex applications, the need to "sign the entire form" or "sign the section" could be performed by concatenating all the items contained by the section or assessment and storing that in a "signed_data" field in as_section_data or as_sessions. However, this would presumably result in duplicate hashing of the data -- once for the individual items and then collectively. Instead, we'll only "sign" the data at the atomic, as_item level, and procedurally sign all as_item_data at once if the assessment author requires only a section-level or assessment-level signature.
- "Events" related to assessments In some applications (like clinical trials), it is important to define a series of "named" assessment events (like "baseline" "one month" "six months" etc) at which time assessments are to be performed. Earlier we included an "event_id" attribute in data collection entities (notably as_item_data) to make mapping of these events to their data easy. This denormalization makes some sense for efficiency considerations, but it doesn't prove to be generally applicable enough to most contexts, so we've removed it. Instead, any client package using Assessment in this fashion should implement its own relationships (presumably with acs_rels).
- "Status" of data collection entities An assessment author may specify different allowable steps for her assessment -- such as whether a user can "save&resume" between sessions, whether a second user needs to "review&confirm" entered data before it becomes "final", etc etc. Rather than try to anticipate these kinds of workflow options (and considering that many uses of Assessment won't want to track any such status), we've decided to move this out of the data model for Assessment per se and into Workflow. Assessment authors will have a UI through which they can configure an applicable workflow (defining states, roles, actions) for the assessment.
Synopsis of Data-Collection Datamodel
Here's the schema for this subsystem:
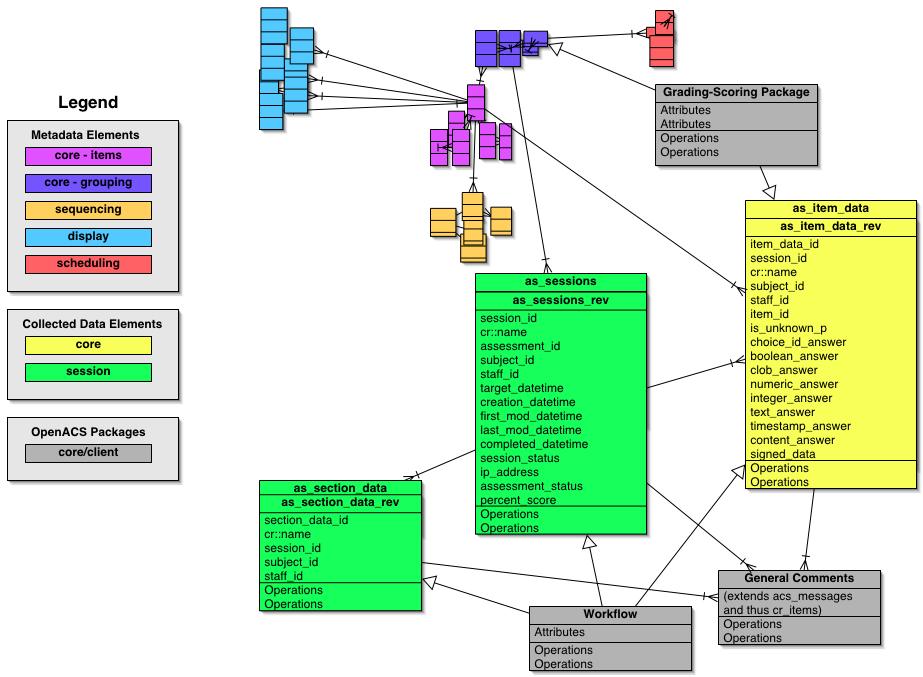
Specific Entities
This section addresses the attributes the most important entities have in the data-collection data model -- principally the various design issues and choices we've made. We omit here literal SQL snippets since that's what the web interface to CVS is for. ;-)
-
Assessment Sessions (as_sessions) are the top
of the data-collection entity hierarchy. They provide the central
definition of a given subject's performance of an Assessment.
Attributes include:
- session_id
- cr::name - Identifier, format
"$session_id-$last_mod_datetime"
- assessment_id (note that this is actually a revision_id)
- subject_id - references a Subjects entity that we don't define in this package. Should reference the parties table as there is no concept of storing persons in OpenACS in general. Note: this cannot reference users, since in many cases, subjects will not be able (or should not be able) to log into the system. The users table requires email addresses. Subjects in Assessment cannot be required to have email addresses. If they can't be "persons" then Assessment will have to define an as_subjects table for its own use.
- staff_id - references Users if someone is doing the Assessment as a proxy for the real subject
- target_datetime - when the subject should do the Assessment
- creation_datetime - when the subject initiated the Assessment
- first_mod_datetime - when the subject first sent something back in
- last_mod_datetime - the most recent submission
- completed_datetime - when the final submission produced a complete Assessment
- ip_address - IP Address of the entry
- percent_score - Current percentage of the subject achieved so far
- consent_timestamp - Time when the consent has been given.
Note, this is a denormalization introduced for the educational application. For clinical trials apps, in contrast, a complete, separate "Enrollment" package will be necessary and would capture consent information. Actually, it's not clear that even for education apps that this belongs here, since a consent will happen only once for a given assessment while the user may complete the assessment during multiple sessions (if save&resume is enabled for instance). In fact, I've removed this from the graffle (SK).
-
Assessment Section Data (as_section_data)
tracks the state of each Section in the Assessment. Attributes
include:
- section_data_id
- cr::name - Identifier, format
"$session_id-$last_mod_datetime"
- session_id
- section_id
- subject_id
- staff_id
-
Assessment Item Data (as_item_data) is the
heart of the data collection piece. This is the "long skinny
table" where all the primary data go -- everything other than
"scale" data ie calculated scoring results derived from
these primary responses from subjects. Attributes include:
- item_data_id
- session_id
- cr::name - identifier in the format "$item_id-$subject_id"
- event_id - this is a foreign key to the "event" during which this assessment is being performed -- eg "second term final" or "six-month follow-up visit" or "Q3 report". Note: adding this here is a denormalization justified by the fact that lots of queries will depend on this key, and not joining against as_sessions will be a Very Good Thing since if a given data submission occurs through multiple sessions (the save&resume situation).
- subject_id
- staff_id
- item_id
- choice_id_answer - references as_item_choices
- boolean_answer
- numeric_answer
- integer_answer
- text_answer -- presumably can store both varchar and text datatypes -- or do we want to separate these as we previously did?
- timestamp_answer
- content_answer - references cr_revisions
- signed_data - This field stores the signed entered data, see above and below for explanations
- percent_score
- To do: figure out how attachment answers should be supported; the Attachment package is still in need of considerable help. Can we rely on it here?
- Assessment Scales : As discussed above, this will for the time being be handled by external grading-scoring-evaluation packages. Assessment will only work with percentages internally. It might be necessary to add scales into assessment as well, but we will think about this once the time arrives, but we think that a more elegant (and appropriate, given the OpenACS toolkit design) approach will be to define service contracts to interface these packages.
- Assessment Annotations provides a flexible way to handle a variety of ways that we need to be able to "mark up" an Assessment. Subjects may modify a response they've already made and need to provide a reason for making that change. Teachers may want to attach a reply to a student's answer to a specific Item or make a global comment about the entire Assessment. This will be achieved by using the General Comments System of OpenACS
-
Signing of content
allows to verify that the data submitted is actually from the
person it is pretended to be from. This assumes a public key
environment where the public key is stored along with the user
information (e.g. with the users table) and the data stored in
as_item_data is additionally stored in a signed version (signed
with the secret key of the user). To verify if the data in
as_item_data is actually verified the system only has to check the
signed_data with the public key and see if it matches the
data.