Overview
At its core, the Assessment package defines a hierarchical container model of a "survey", "questionnaire" or "form". This approach not only follows the precedent of existing work; it also makes excellent sense and no one has come up with a better idea.
- One Assessment consists of
- One or more Sections which each consist of
- One or more Items which have
- Zero or more Choices
We choose the terms Assessment-Sections-Items-Choices over Surveys-Sectdions-Questions-Choices partly to reduce naming clashes during the transition from Survey/Questionnaire packages, but mostly because these terms are more general and thus suit the broader applicability intended for this package.
As is the custom in the OpenACS framework, all RDBMS tables in the package will be prepended with "as_" to prevent further prefent naming clashes. Judicious use of namespaces will also be made in keeping with current OpenACS best practice.
Several of the Metadata entities have direct counterparts in the Data-related partition of the data model. Some standards (notably CDISC) rigorously name all metadata entities with a "_def" suffix and all data entities with a "_data" suffix -- thus "as_item_def" and "as_item_data" tables in our case. We think this is overkill since there are far more metadata entities than data entities and in only a few cases do distinctions between the two become important. In those cases, we will add the "_data" suffix to data entities to make this difference clear.
A final general point (that we revisit for specific entities below): the Assessment package data model exercises the Content Repository (CR) in the OpenACS framework heavily. In fact, this use of the CR for most important entities represents one of the main advances of this package compared to the earlier versions. The decision to use the CR is partly driven by the universal need for versioning and reuse within the functional requirements, and partly by the fact that the CR has become "the Right Way" to build OpenACS systems. Note that one implication of this is that we can't use a couple column names in our derived tables because of naming clashes with columns in cr_items and cr_revisions: title and description. Furthermore we can handle versioning and internationalization through the CR.
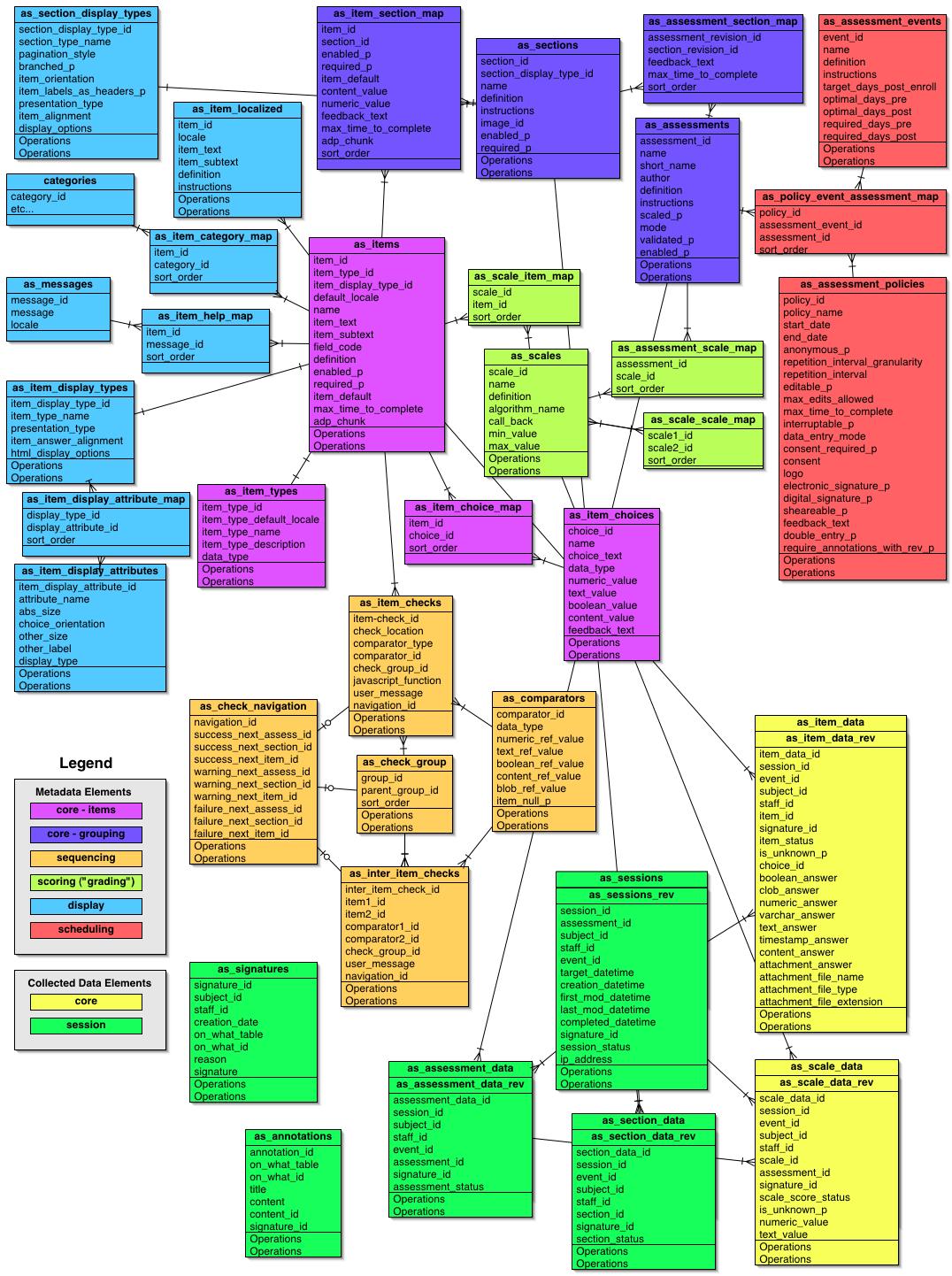
Synopsis of The Data Model
Here's a detailed summary view of the entities in the Assessment package. Note that in addition to the partitioning of the entities between Metadata Elements and Collected Data Elements, we identify the various subsystems in the package that perform basic functions.
We discuss the following stuff in detail through the subsequent pages, and we use a sort of "bird's eye view" of this global graphic to keep the schema for each subsystem in perspective while homing in on the relevant detail. Here's a brief introduction to each of these section- core - items entities (purple) define the structure and semantics of Items, the atomic units of the Assessment package
- core - grouping entities (dark blue) define constructs that group Items into Sections and Assessments
- sequencing entities (yellow-orange) handle data validation steps and conditional navigation derived from user responses
- scoring ("grading") entities (yellow-green) define how raw user responses are to be processed into calculated numeric values for a given Assessment
- display entities (light blue) define constructs that handle how Items are output into the actual html forms returned to users for completion -- including page layout and internationalization characteristics
- scheduling entities define mechanisms for package administrators to set up when, who and how often users should perform an Assessment
- session data collection entities (bright green) define entities that store information about user data collection events -- notably session status and activities that change that status as the user users the system