
Forum OpenACS Development: Re: Roadmap: How does Openacs Scale?
We use in our learn@wu system a tailored version of oacs+dotlrn+own packages and managed a very acceptable performance for an highly intensively used system (we have more than 25000 learning resources, most of these are interactive, auto-evaluated questions with immediate feedback; our students solve up to 20.000 to 30.000 exercises per hour over the system). We have now with 1.000 concurrently active users average response times of below 0.2 seconds per view on our new system.
Checkout about our history from the slides of the DotLrn workshops in Heidelberg and Madrid. Our new machine is a p570 with 8 POWER5 processors, which runs like a champ. 6 of these processors are used for a logical partition running the aolserver for dynamic requests and the PostgreSQL database. I can't talk here about prices, but we got a public grant for hardware from our ministry and very good offers from the vendor that made this improvement possible. We use a second small 2proc Intel machine as proxy and with an aolserver for serving logos, style-files, etc.
Our previous systems consisted of two 8-processor Intel xeon machines (one for the database, one for dynamic requests) which worked fine up to 1000 users. We run into two limitations: the database server was by far not able to use all processors (i think, a 4 processor machine would be as performant as our 8 processor machine for our setup) and the size of the aolserver was hitting the 32bit address limitations due to our 50 connection threads. The scalability problem of the old database server was most likely due to the postgres architecture and limited memory bandwidth and latency from the Intel server (which has btw., quite good spec_int rate values). The new machine is 64 bit, and scales very well over all processors for our kind of application.
It is not quite easy to get meaningful benchmark numbers for throughput based applications, esp. since we did not want to change the database etc. So, Peter Alberer from our learn@wu project team wrote a benchmark system based on our request patterns that we used to benchmark some systems. Please note that these benchmark are in no way official benchmarks, they might be totally misleading for a different setup. Maybe with PostgreSQL 8.1, everything has changed already. All benchmark results are under Linux with a recent 2.6 kernel and postgres 8.0.
We tested various 64 bit MP-machines. When we made the tests we had more or less the choice btwn. Opteron and POWER 5. The Intel machines were clearly slower than the Opteron, we had already bad experience the the xSeries 445 machine, the future of Itanium based systems looked unclear to us. We were as well limited in the configurations we could bet for benchmarking.
The table below shows some of the most interesting figures. Learn-bench is the throughput of our benchmark, higher numbers are better. Note that e.g. spec_int_rate2000 differs significantly form our throughput values. We tried to collect various other benchmark results (such as HPC, HPC Linux, TPCH, OMPM, rperf), however, we did not find it easy to find for the hardware of question comparable and meaningful benchmark results. IBM's rperf had the best correlation to our benchmark, but it is only IBM only).
Ratio means the performance ratio relative to our old 8-proc-based machine. Users is the estimated number of users for our kind of application (based on experience; the old setup with two machines peaked at 1000 users, this would related roughly to 700 users on a single machine). The values for the machines different to the x445 are estimated values due to our benchmark results.
The views per seconds are measured values from our usage patterns. Many views involve 10 or more SQL queries. I noticed, that Mannheim has significantly less views/user/seconds, which is most probable due to the fact that we have these many interactive exercises. Therefore the numbers of users would be much greater with lower page view ratios.
Don't base any buying decision on these numbers, it is a little piece of information about current products without any claims for significance.
<span style="font-size: 80%">
<table border=0 >
<tr>
<td >Machine</td>
<td >Chips</td>
<td >Cores</td>
<td >GHz</td>
<td >GB</td>
<td >SPECint_rate2000</td>
<td >Learn-Bench</td>
<td >Ratio</td>
<td >Concurrent Users</td>
<td >Views/sec</td>
</tr>
<tr>
<td >IBM xSeries 445 (Xeon)</td>
<td align=right>8</td>
<td align=right>8</td>
<td align=right>2,7</td>
<td align=right>8</td>
<td align=right>75,20</td>
<td align=right>45,00</td>
<td align=right>1,00</td>
<td align=right>700</td>
<td align=right>21</td>
</tr>
<tr>
<td >IBM OpenPower 720</td>
<td align=right>2</td>
<td align=right>4</td>
<td align=right>1,65</td>
<td align=right>8</td>
<td align=right>59,80</td>
<td align=right>88,00</td>
<td align=right>1,96</td>
<td align=right>1369</td>
<td align=right>41</td>
</tr>
<tr>
<td >IBM pSeries 570</td>
<td align=right>4</td>
<td align=right>8</td>
<td align=right>1,9</td>
<td align=right>16</td>
<td align=right>147,00</td>
<td align=right>178,89</td>
<td align=right>3,98</td>
<td align=right>2783</td>
<td align=right>83</td>
</tr>
<tr>
<td >IBM pSeries 570</td>
<td align=right>8</td>
<td align=right>16</td>
<td align=right>1,9</td>
<td align=right>16</td>
<td align=right>294,00</td>
<td align=right>372,24</td>
<td align=right>8,27</td>
<td align=right>5790</td>
<td align=right>174</td>
</tr>
<tr>
<td >IBM pSeries 575</td>
<td align=right>8</td>
<td align=right>8</td>
<td align=right>1,9</td>
<td align=right>16</td>
<td align=right>167,00</td>
<td align=right>196,71</td>
<td align=right>4,37</td>
<td align=right>3060</td>
<td align=right>92</td>
</tr>
<tr>
<td >Sun V40z (Opteron)</td>
<td align=right>4</td>
<td align=right>4</td>
<td align=right>2,6</td>
<td align=right>16</td>
<td align=right>76,70</td>
<td align=right>70,00</td>
<td align=right>1,56</td>
<td align=right>1089</td>
<td align=right>33</td>
</tr>
<tr>
<td >HP DL585 (Opteron)</td>
<td align=right>4</td>
<td align=right>8</td>
<td align=right>2,2</td>
<td align=right>32</td>
<td align=right>130,00</td>
<td align=right>135,59</td>
<td align=right>3,01</td>
<td align=right>2109</td>
<td align=right>63</td>
</tr>
</table>
</span>
Are you running everything in the same box, right? (PG & nsd).
Is this box running only one nsd process?
Are you restarting your nsd daily?
Do you still see "unable to alloc" aolserver crashes?
How did you performed these tests? (tools, special stuff you developed), if you are able, give details.
Many questions.... :-)
yes, in all test-cases db+nsd were running on the same box. For these test-cases, there we used only one nsd process with 40 connection threads.
on our production system (often more than 1200 concurrent users, with average response time of < 0.2 secods, about 1.5 mio oacs objects) we have the same setup, everything on one box. we got the p570 with 16 cores, every core has the equivalent to hyperthreading, therefore we have 32 cpus, which are split between 2 lpars (logical partions, like a vm, every lpar might have different operating systems, different cpus and devices assigned etc). we are running in 64-bit linux. the power5+ achitecture has a great memory bandwith and low latency, this seems the reason why it scales so well. This is a great hardware with the disadvantage that we are getting more lazy about performance tuning.
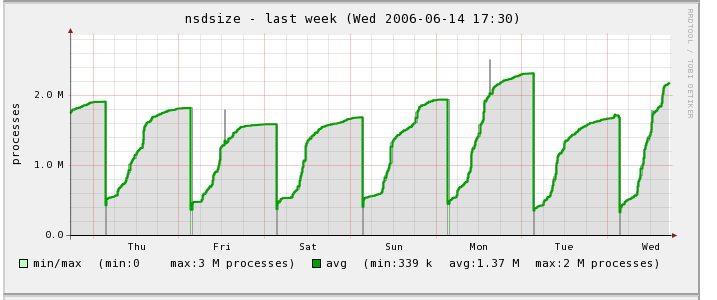
yes, we are still rebooting nsd daily. the unable to alloc messages are gone, since we changed to 64 bit. The size of nsd grows in our current setup to about 2GB. You see in the graph nsd growing from the reboot at 3:30am
http://media.wu-wien.ac.at/download/nsdsize.png
without reboot it reaches about twice the size on the second day, the growth seems highly related to the number of requests.
{kind=link}
the tests of the benchmark: peter alberer did this. we monitored our usage pattern, developed from that a mix of of queries on the tcl api level (our inhouse developed online execises, forums, etc) configured these to run without or faked ad_conn info, defined a user-session constisting of these tasks, and run these tasks in multiple threads (using libthread). For this, we used a reasonably sized database (>1 mio oacs objects). The results are the figures in Learn-Bench.
It was not so easy to get access to these machines to run our tests. IBM and one of its local dealers were quite helpful, so we got more results about this family. we were not keen on itanium systems, since the price was high and the future unclear.
i can't and won't claim that our benchmarks are significant for anybody execpt us. we have a different load pattern and our installations differs in about 11.000 changes from current oacs-5-2. most probably, there are now much faster or cheaper machines out there, than we got access to about one year ago.
in what kind of information are you interested?