Created by Anett Szabo, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
API testing is only part of testing your package - it doesn't test the code in our adp/tcl pairs. For this, we can use TCLWebtest (see sourceforge).
TclWebtest is primarily for testing user interface and acceptance testing. It is a tool to write automated tests for web applications. It provides a simple API for issuing http requests, dealing with the result and assume specific response values, while taking care of the details such as redirects and cookies.
It has some basic html parsing functionality, to provide access to elements of the result html page that are needed for testing (mainly links and forms).
- TCLWebtest provides a library of functions (see command reference) that make it easy to call a page through HTTP, examine the results, and drive forms. TCLwebtest's functions overlap slightly with acs-automated-testing; see the example provided for one approach on integrating them.
- TCLWebtest tries to minimize the effort to write tests by implicitely assuming specific conditions whenever it makes sense. For example it always expects the server to return http codes other than 404 or 500, unless otherwise specified.
- The assertion procedures are targeted at test writers who want to make sure the behaviour of their web applications stays the same, without caring for style or minor wording changes. In the example below, it is just assumed that there is a link with the text "login" on the first page, that clicking on it results in a page with at least one form with at least two text-entry fields on it, and that submitting the form with the specified values results in a page that contains the "logged in" text.
- TCLWebtest should be suitable for testing larger chains of user interaction on a web application, for example a full ecommerce ordering session. tclwebtest could visit an ecommerce site as anonymous user, add some products to its shopping cart, check out the cart, register itself as user and enter a test address etc. The test script could also include the administration part of the interaction, by explicitely logging in as site admin, reviewing and processing the order, nuking the test user etc.
- TCLWebtest must be installed for to work. Since automated testing uses it, it should be part of every OpenACS installation. Note that TCLwebtest is installed automatically by Malte's install script.
Hint:
In order to simplify the generation of tclwebtest scripts the Webtest-Recorder extension (TwtR) for Firefox is available see http://www.km.co.at/km/twtr This module is a plugin for Firefox. It is used to generate/edit a tclwebtest script which can be used later for regression testing without the need of a browser. There is a certain overlap of the application range between selenium and TwtR. This plugin was developed by Ã
smund Realfsen for regression/load testing of the assessment module.
A typical script for tclwebtest looks like this:
set SERVER "testserver"
do_request "http://$SERVER/sometesturl/"
assert text "some text"
link follow "login"
field fill "testuser"
field fill "testpassword"
form submit
assert text "you are logged in as testuser"
This script can be saved in a file, e.g.
login.test, and executed with
./tclwebtest login.test. The script itself is tcl, so you can do powerful things with only a few commands.
http://cvs.openacs.org/cvs/openacs-4/etc/install/tcl/twt-procs.tcl?rev=1.18
Command Reference:
Here are some guidelines on how to write automated tests with TCLWebtest. It is a joy to work with automated testing once you get the hang of it. We will use the "myfirstpackage" as an example.
Create the directory that will contain the test script and edit the script file. The directory location and file name are standards which are recognized by the automated testing package:
[$OPENACS_SERVICE_NAME www]$ mkdir /var/lib/aolserver/$OPENACS_SERVICE_NAME/packages/myfirstpackage/tcl/test
[$OPENACS_SERVICE_NAME www]$ cd /var/lib/aolserver/$OPENACS_SERVICE_NAME/packages/myfirstpackage/tcl/test
[$OPENACS_SERVICE_NAME test]$ emacs myfirstpackages-procs.tcl
Write the tests. This is obviously the big step :) The script should first call ad_library like any normal -procs.tcl file:
ad_library {
...
}
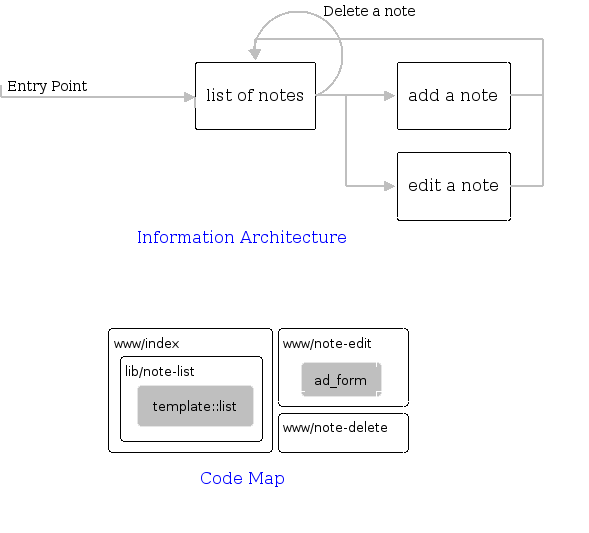
To create a test case you call aa_register_case test_case_name.. Once you've created the test case you start writing the needed logic. We'll use the tutorial package, "myfirstpackage," as an example. Let's say you just wrote an API for adding and deleting notes in the notes packages and wanted to test that. You'd probably want to write a test that first creates a note, then verifies that it was inserted, then perhaps deletes it again, and finally verifies that it is gone.
Naturally this means you'll be adding a lot of bogus data to the database, which you're not really interested in having there. To avoid this I usually do two things. I always put all my test code inside a call to aa_run_with_teardown which basically means that all the inserts, deletes, and updates will be rolled back once the test has been executed. A very useful feature. Instead of inserting bogus data like: set name "Simon", I tend to generate a random script in order avoid inserting a value that's already in the database:
set name [ad_generate_random_string]
Here's how the test case looks so far:
aa_register_case mfp_basic_test {
My test
} {
aa_run_with_teardown -rollback -test_code {
}
}
Now look at the actual test code. That's the code that goes inside -test_code {}. We want to implement test case API-001, "Given an object id from API-001, invoke mfp::note::get. Proc should return the specific word in the title."
set name [ad_generate_random_string]
set new_id [mfp::note::add -title $name]
aa_true "Note add succeeded" [exists_and_not_null new_id]
To test our simple case, we must load the test file into the system (just as with the /tcl file in the basic tutorial, since the file didn't exist when the system started, the system doesn't know about it.) To make this file take effect, go to the APM and choose "Reload changed" for "MyFirstPackage". Since we'll be changing it frequently, select "watch this file" on the next page. This will cause the system to check this file every time any page is requested, which is bad for production systems but convenient for developing. We can also add some aa_register_case flags to make it easier to run the test. The -procs flag, which indicates which procs are tested by this test case, makes it easier to find procs in your package that aren't tested at all. The -cats flag, setting categories, makes it easier to control which tests to run. The smoke test setting means that this is a basic test case that can and should be run any time you are doing any test. (a definition of "smoke test")
Once the file is loaded, go to ACS Automated Testing and click on myfirstpackage. You should see your test case. Run it and examine the results.
Example
Now we can add the rest of the API tests, including a test with deliberately bad data. The complete test looks like:
ad_library {
Test cases for my first package.
}
aa_register_case -cats {smoke api} -procs {mfp::note::add mfp::note::get mfp::note::delete} mfp_basic_test {
A simple test that adds, retrieves, and deletes a record.
} {
aa_run_with_teardown -rollback -test_code {
set name [ad_generate_random_string]
set new_id [mfp::note::add -title $name]
aa_true "Note add succeeded" [exists_and_not_null new_id]
# Now check that the item exists
mfp::note::get -item_id $new_id -array note_array
aa_true "Note contains correct title" [string equal $note_array(title) $name]
# Now check, if titel got the value of name
mfp::note::delete -item_id $new_id
set get_again [catch {mfp::note::get -item_id $new_id -array note_array}]
aa_false "After deleting a note, retrieving it fails" [expr $get_again == 0]
}
}
aa_register_case -cats {api} -procs {mfp::note::add mfp::note::get mfp::note::delete} mfp_bad_data_test {
A simple test that adds, retrieves, and deletes a record, using some tricky data.
} {
aa_run_with_teardown -rollback -test_code {
set name {-Bad [BAD] \077 { $Bad}}
#Now name becomes this very unusual value: -Bad [BAD] \077 { $Bad}
append name [ad_generate_random_string]
set new_id [mfp::note::add -title $name]
#Now new_id becomes the value of the solution of proceduer add with starting argument $name as -title
aa_true "Note add succeeded" [exists_and_not_null new_id]
#Now test that new_id exists
mfp::note::get -item_id $new_id -array note_array
aa_true "Note contains correct title" [string equal $note_array(title) $name]
aa_log "Title is $name"
mfp::note::delete -item_id $new_id
set get_again [catch {mfp::note::get -item_id $new_id -array note_array}]
aa_false "After deleting a note, retrieving it fails" [expr $get_again == 0]
}
}
aa_register_case
-cats {web smoke}
-libraries tclwebtest
mfp_web_basic_test
{
A simple tclwebtest test case for the tutorial demo package.
@author Peter Marklund
} {
# we need to get a user_id here so that it's available throughout
# this proc
set user_id [db_nextval acs_object_id_seq]
set note_title [ad_generate_random_string]
# NOTE: Never use the aa_run_with_teardown with the rollback switch
# when running Tclwebtest tests since this will put the test code in
# a transaction and changes won't be visible across HTTP requests.
aa_run_with_teardown -test_code {
#-------------------------------------------------------------
# Login
#-------------------------------------------------------------
# Make a site-wide admin user for this test
# We use an admin to avoid permission issues
array set user_info [twt::user::create -admin -user_id $user_id]
# Login the user
twt::user::login $user_info(email) $user_info(password)
#-------------------------------------------------------------
# New Note
#-------------------------------------------------------------
# Request note-edit page
set package_uri [apm_package_url_from_key myfirstpackage]
set edit_uri "${package_uri}note-edit"
aa_log "[twt::server_url]$edit_uri"
twt::do_request "[twt::server_url]$edit_uri"
# Submit a new note
tclwebtest::form find ~n note
tclwebtest::field find ~n title
tclwebtest::field fill $note_title
tclwebtest::form submit
#-------------------------------------------------------------
# Retrieve note
#-------------------------------------------------------------
# Request index page and verify that note is in listing
tclwebtest::do_request $package_uri
aa_true "New note with title \"$note_title\" is found in index page"
[string match "*${note_title}*" [tclwebtest::response body]]
#-------------------------------------------------------------
# Delete Note
#-------------------------------------------------------------
# Delete all notes
# Three options to delete the note
# 1) go directly to the database to get the id
# 2) require an API function that takes name and returns ID
# 3) screen-scrape for the ID
# all options are problematic. We'll do #1 in this example:
set note_id [db_string get_note_id_from_name "
select item_id
from cr_items
where name = :note_title
and content_type = 'mfp_note'
" -default 0]
aa_log "Deleting note with id $note_id"
set delete_uri "${package_uri}note-delete?item_id=${note_id}"
twt::do_request $delete_uri
# Request index page and verify that note is in listing
tclwebtest::do_request $package_uri
aa_true "Note with title \"$note_title\" is not found in index page after deletion."
![string match "*${note_title}*" [tclwebtest::response body]]
} -teardown_code {
twt::user::delete -user_id $user_id
}
}
Created by Gustaf Neumann, last modified by Malte Sussdorff 07 Aug 2007, at 04:18 PM
A good detailed, yet somewhat outdated
article is written by
Reuven Lerner for the Linux Journal. It gives a good introduction, but
please read on !
OpenACS (Open Architecture Community System) is an
advanced toolkit for building scalable, community-oriented
web applications. If you're thinking of building an
enterprise-level web application, OpenACS is a solid,
scalable framework for building dynamic content driven
sites.
OpenACS is a collection of pre-built applications and
services that you can use to build your web
site/application. Through a modular architecture, OpenACS
has packages for user/groups management, content
management, e-commerce, news, FAQs, calendar, forums, bug
tracking, full-text searching, and much
more.
OpenACS relies on AOLserver, the
free, multithreaded, scalable, Tcl-enabled,
web/application server used by America Online for most of
its web sites, and a true ACID-compliant Relational
Database Management System (RDBMS). Currently OpenACS
supports PostgreSQL, an open source RDBMS, and Oracle and
is easily extensible to other databases which support a
comparable feature set.
The OpenACS toolkit is derived from the ArsDigita
Community System (ACS). ArsDigita (now part of Red Hat,
Inc.) kindly made their work available under the GPL,
making all of this possible.
The OpenACS project was born when Don Baccus, Ben Adida, and
others decided to port ACS from Oracle to PostgreSQL, thus
making it a fully open-source solution. With OpenACS 4,
Oracle and PostgreSQL support were combined in one code base
and with OpenACS 5, support for internationalization and
localization has been added.
A vibrant and productive community has sprung up around the
OpenACS software and there are many volunteer contributors
as well as a commercial companies able to provide support,
hosting, and custom development. Many of the production
users are actively funding and contributing work back to the
project. Formal, consensus driven governance has been
established (with semi-annual elections) which ensures the
project serves the needs of it's constituents.
The OpenACS community would like to hear your comments and
can help you in your endeavors with the system. Visit our
web site and feel
free to ask questions or provide feedback.
Created by Anett Szabo, last modified by Malte Sussdorff 25 Jul 2007, at 05:57 PM
Data modeling is the hardest and most important activity in the RDBMS
world. If you get the data model wrong, your application might not do
what users need, it might be unreliable, it might fill up the database
with garbage. Why then do we start a SQL tutorial with the most
challenging part of the job? Because you can't do queries, inserts, and
updates until you've defined some tables. And defining tables is
data
modeling.
When data modeling, you are telling the RDBMS the following:
- what elements of the data you will store
- how large each element can be
- what kind of information each element can contain
- what elements may be left blank
- which elements are constrained to a fixed range
- whether and how various tables are to be linked
Three-Valued Logic
Programmers in most computer languages are familiar with Boolean logic.
A variable may be either true or false. Pervading SQL, however, is
the alien idea of
three-valued logic. A column can be true,
false, or NULL. When building the data model you must affirmatively
decide whether a NULL value will be permitted for a column and, if so,
what it means.
For example, consider a table for recording user-submitted comments to a
Web site. The publisher has made the following stipulations:
- comments won't go live until approved by an editor
- the admin pages will present editors with all comments that are
pending approval, i.e., have been submitted but neither approved nor
disapproved by an editor already
Here's the data model:
create table user_submitted_comments (
comment_id integer primary key,
user_id not null references users,
submission_time date default sysdate not null,
ip_address varchar(50) not null,
content clob,
approved_p char(1) check(approved_p in ('t','f'))
);
Implicit in this model is the assumption that
approved_p
can be NULL and that, if not explicitly set during the INSERT, that is
what it will default to. What about the check constraint? It would
seem to restrict
approved_p to values of "t" or "f". NULL,
however, is a special value and if we wanted to prevent
approved_p from taking on NULL we'd have to add an explicit
not null constraint.
How do NULLs work with queries? Let's fill
user_submitted_comments with some sample data and see:
insert into user_submitted_comments
(comment_id, user_id, ip_address, content)
values
(1, 23069, '18.30.2.68', 'This article reminds me of Hemingway');
Table created.
SQL> select first_names, last_name, content, user_submitted_comments.approved_p
from user_submitted_comments, users
where user_submitted_comments.user_id = users.user_id;
FIRST_NAMES LAST_NAME CONTENT APPROVED_P
------------ --------------- ------------------------------------ ------------
Philip Greenspun This article reminds me of Hemingway
We've successfully JOINed the
user_submitted_comments and
users table to get both the comment content and the name of
the user who submitted it. Notice that in the select list we had to
explicitly request
user_submitted_comments.approved_p. This is because
the
users table also has an
approved_p
column.
When we inserted the comment row we did not specify a value for the
approved_p column. Thus we expect that the value would be
NULL and in fact that's what it seems to be. Oracle's SQL*Plus
application indicates a NULL value with white space.
For the administration page, we'll want to show only those
comments where the approved_p column is NULL:
SQL> select first_names, last_name, content, user_submitted_comments.approved_p
from user_submitted_comments, users
where user_submitted_comments.user_id = users.user_id
and user_submitted_comments.approved_p = NULL;
no rows selected
"No rows selected"? That's odd. We know for a fact that we have one
row in the comments table and that is
approved_p column is
set to NULL. How to debug the query? The first thing to do is simplify
by removing the JOIN:
SQL> select * from user_submitted_comments where approved_p = NULL;
no rows selected
What is happening here is that any expression involving NULL evaluates
to NULL, including one that effectively looks like "NULL = NULL". The
WHERE clause is looking for expressions that evaluate to true. What you
need to use is the special test IS NULL:
SQL> select * from user_submitted_comments where approved_p is NULL;
COMMENT_ID USER_ID SUBMISSION_T IP_ADDRESS
---------- ---------- ------------ ----------
CONTENT APPROVED_P
------------------------------------ ------------
1 23069 2000-05-27 18.30.2.68
This article reminds me of Hemingway
An adage among SQL programmers is that the only time you can use
"= NULL" is in an UPDATE statement (to set a column's value to
NULL). It never makes sense to use "= NULL" in a WHERE clause.
The bottom line is that as a data modeler you will have to decide which
columns can be NULL and what that value will mean.
Back to the Mailing List
Let's return to the mailing list data model from the introduction:
create table mailing_list (
email varchar(100) not null primary key,
name varchar(100)
);
create table phone_numbers (
email varchar(100) not null references mailing_list,
number_type varchar(15) check (number_type in ('work','home','cell','beeper')),
phone_number varchar(20) not null
);
This data model locks you into some realities:
- You will not be sending out any physical New Year's cards to folks
on your mailing list; you don't have any way to store their addresses.
- You will not be sending out any electronic mail to folks who work at
companies with elaborate Lotus Notes configurations; sometimes Lotus
Notes results in email addresses that are longer than 100 characters.
- You are running the risk of filling the database with garbage since
you have not constrained phone numbers in any way. American users could
add or delete digits by mistake. International users could mistype
country codes.
- You are running the risk of not being able to serve rich people
because the
number_type column may be too constrained.
Suppose William H. Gates the Third wishes to record some extra phone
numbers with types of "boat", "ranch", "island", and "private_jet". The
check (number_type in ('work','home','cell','beeper'))
statement prevents Mr. Gates from doing this.
- You run the risk of having records in the database for people whose
name you don't know, since the
name column of
mailing_list is free to be NULL.
- Changing a user's email address won't be the simplest possible
operation. You're using
email as a key in two tables and
therefore will have to update both tables. The references
mailing_list keeps you from making the mistake of only updating
mailing_list and leaving orphaned rows in
phone_numbers. But if users changed their email addresses
frequently, you might not want to do things this way.
- Since you've no provision for storing a password or any other means
of authentication, if you allow users to update their information, you
run a minor risk of allowing a malicious change. (The risk isn't as
great as it seems because you probably won't be publishing the complete
mailing list; an attacker would have to guess the names of people on
your mailing list.)
These aren't necessarily bad realities in which to be locked. However,
a good data modeler recognizes that every line of code in the .sql file
has profound implications for the Web service.
To get some more information on how a simple datamodel for a Discussion Forum can evolve, read en:sql-wn-data_modeling-philip
Representing Web Site Core Content
Free-for-all Internet discussions can often be useful and occasionally
are compelling, but the anchor of a good Web site is usually a set of
carefully authored extended documents. Historically these have tended
to be stored in the Unix file system and they don't change too often.
Hence I refer to them as
static pages. Examples of static
pages on the photo.net server include this book chapter, the tutorial on
light for photographers at
http://www.photo.net/making-photographs/light.
We have some big goals to consider. We want the data in the database to
- help community experts figure out which articles need revision and
which new articles would be most valued by the community at large.
- help contributors work together on a draft article or a new version
of an old article.
- collect and organize reader comments and discussion, both for
presentation to other readers but also to assist authors in keeping
content up-to-date.
- collect and organize reader-submitted suggestions of related content
out on the wider Internet (i.e., links).
- help point readers to new or new-to-them content that might interest
them, based on what they've read before or based on what kind of content
they've said is interesting.
The big goals lead to some more concrete objectives:
- We will need a table that holds the static pages themselves.
- Since there are potentially many comments per page, we need a
separate table to hold the user-submitted comments.
- Since there are potentially many related links per page, we need a
separate table to hold the user-submitted links.
- Since there are potentially many authors for one page, we need a
separate table to register the author-page many-to-one relation.
- Considering the "help point readers to stuff that will interest
them" objective, it seems that we need to store the category or
categories under which a page falls. Since there are potentially many
categories for one page, we need a separate table to hold the mapping
between pages and categories.
create table static_pages (
page_id integer not null primary key,
url_stub varchar(400) not null unique,
original_author integer references users(user_id),
page_title varchar(4000),
page_body clob,
obsolete_p char(1) default 'f' check (obsolete_p in ('t','f')),
members_only_p char(1) default 'f' check (members_only_p in ('t','f')),
price number,
copyright_info varchar(4000),
accept_comments_p char(1) default 't' check (accept_comments_p in ('t','f')),
accept_links_p char(1) default 't' check (accept_links_p in ('t','f')),
last_updated date,
-- used to prevent minor changes from looking like new content
publish_date date
);
create table static_page_authors (
page_id integer not null references static_pages,
user_id integer not null references users,
notify_p char(1) default 't' check (notify_p in ('t','f')),
unique(page_id,user_id)
);
Note that we use a generated integer
page_id key for this
table. We could key the table by the
url_stub (filename),
but that would make it very difficult to reorganize files in the Unix
file system (something that should actually happen very seldom on a Web
server; it breaks links from foreign sites).
How to generate these unique integer keys when you have to insert a new
row into static_pages? You could
- lock the table
- find the maximum
page_id so far
- add one to create a new unique
page_id
- insert the row
- commit the transaction (releases the table lock)
Much better is to use Oracle's built-in sequence generation facility:
create sequence page_id_sequence start with 1;
Then we can get new page IDs by using
page_id_sequence.nextval in INSERT statements (see
the Transactions chapter for a fuller
discussion of sequences).
Reference
Here is a summary of the data modeling tools available to you in
Oracle, each hyperlinked to the Oracle documentation. This reference
section covers the following:
---
based on SQL for Web Nerds