*** Use categories for project status?
I think we also need to look into workflow here. I think this is exactly what workflow is for (managing the states between transitions). Otherwise, I think we could create a project_status table to store all the possible states of a project, and perhaps another table to store the valid transitions or something like that. The ACS 3.4 projects allowed you to arbitrarily set the state of the project.
Torben, I think another part of what you're saying with project status can be said another way: there are stages to a project, and those stages should be properly broken down into sub-projects, so that information for each stage is kept distinct. There might be documents attached to the Requirements sub-project, for example. But this should be determined by the project manager. It's their choice of how to break things down.
But I also might be missing what you're saying here.
What I'm thinking with project status: it's just a tag. Let's say your company decided the valid status values for a project are "Planning" "In development" "Completed". Then any project would need to be in one of those three values.
We can do this either with a separate table or with workflow. I haven't looked very much into workflow yet.
*** Terminology
Can we get an edit-this-page instance set up with a "terminology" page? If I'm given write access to this, I'll maintain it.
*** Day and time units for estimates
Torben, I think what you're suggesting is using timestamptz instead of number for the day and time estimates in dp_task.
The reason I separated the day and time units for Task Estimates is this:
Imagine you have a task that you think will take three days to accomplish, but only 2 hours of real work. The reason for that might be that it is a painting job, and you have to wait a day in between each painting to let things dry. This is a contrived example, but not unrealistic, I think.
How would you suggest improving this? I'm not really clear on what the alternative is.
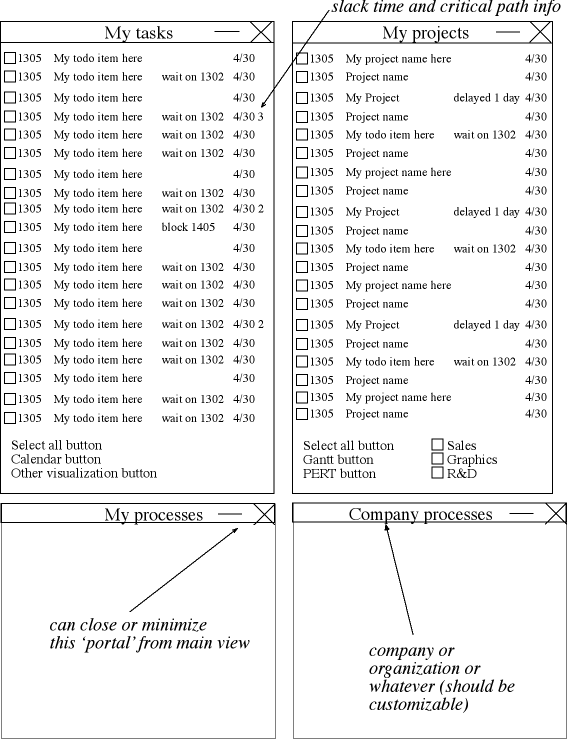
*** Slack time
I'm not clear on what RTV is (relative time value).
If the person enters the low and high estimates of how long they think the task will take to accomplish, the slack time could be calculated.
*** It looks like we'll need to define Project Roles as a table.
I've added this into the data model, and put in some comments about implications of the way I have it set up now. I would welcome comments on proposed changes to this.
*** Changes to the data model (it's not my data model any more! 😊
- I took out deadline for dp_tasks. It didn't make sense, since end_date was already present.
- added in a table to keep track of users' project roles.
- I copied a lot from Nick's data model
*** Re: Nick's suggestions for the data model
In projects:
Is the owner the person who creates the project? If so, this is already created using the object system. Is there is another reason for having this? Same point with author. Also, I think author should refer to the users table.
I suggest we name all the tables with a prefix (whatever we decide on), to avoid namespace collisions. I've used "dp" (for dotProject), but we could use whatever the community agrees upon.
Category should probably refer to another table, not just a varchar. Actually, we might be able to take it out entirely. We'll need to look at the categorization package.
Company should refer to a company table. Good point. Should we build this from scratch? I know Jon Griffin has done some related work. See http://jongriffin.com/static/openacs/packages/ and look at his organizations package. It's still version 0.1d, so I'm not sure if it's a good idea to build on top of it or not. But if he's planning on building that out better, then perhaps we can just build on top of his Organizations package. That would give us things like Vendors, Customers, etc... If we decide to go with that, then we'll refer to the organizations table. I'll do that in the data model I'm working on.
Status date refers to the date that the status was most recently changed?
I'm not sure about putting manager in the project table. The implication of this is that there can only be one manager per project. I'm not sure if this is flexible enough. Do we want the ability to assign more than one person to a project?
In the ACS 3.4 Intranet, you had to explicitly assign people to be a part of a project. Then you assign people to tickets to do things associated with that project. I think a better way to do it would be that anybody assigned any Task on a Project would be on the project.
Do we then need a mapping of "which users see which projects"? Maybe so. I'll put that in my data model...
I'm not sure what "subject" does.
I also don't really understand what these are:
hours_per_day integer, -- 0 to 24
days_per_month integer, -- 0 to 32
week_start_day integer, -- 0 to 6
year_start_month integer, -- 0 to 12
hours_per_week integer, -- 0 to 168
I like the division between planned and actual. Very good idea. I'll add those to tasks as well, so we can track how much time versus actual time.
Not sure what planned_work means, especially as an integer.
I haven't been thinking much about cost and resource tracking yet.
Not sure what baseline means:
baseline_start DATE,
baseline_finish DATE,
baseline_duration integer,
baseline_work integer,
baseline_cost integer,
Should we put the amount of remaining work to do in the data model? Or should that be computed based on the Tasks yet to be completed?
What is acwp, bcwp, bcws?
I'm not sure what you're doing with these:
start_variance integer,
finish_variance integer,
cost_variance integer,
early_start DATE,
early_finish DATE,
late_start DATE,
late_finish DATE,
Do we put these in the data model, or compute them?
total_slack integer,
free_slack integer
*** Response to Malte's comments: good idea about allowing more than one organization to be associated with a project. There could in fact be several, especially for complicated projects. Also, for example, there might be a separate distributor and manufacturer, for example. So, let's separate those out.
I'm not sure about how to break out the timing as you suggest. Any more concrete suggestions?
*** Regarding Dave's comment: I think we will need a calendar package to be (re)written. Eventually, all of this stuff will need to have several views, one of which is a calendar.
I'm going to work on the data model a little more, and then post a revised version. I might post it on my website, so I don't have to clutter up this forum with every revision.

{kind=link}