Releasing OpenACS
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
Download the Analog source tarball in /tmp. Unpack, compile, and install analog.
[root aolserver]#cd /usr/local/src[root src]#tar xzf /tmp/analog-5.32.tar.gz[root src]#cd analog-5.32[root analog-5.32]#makecd src && make make[1]: Entering directory `/usr/local/src/analog-5.32/src' (many lines omitted) ***IMPORTANT: You must read the licence before using analog *** make[1]: Leaving directory `/usr/local/src/analog-5.32/src' [root analog-5.32]#cd ..[root src]#mv analog-5.32 /usr/share/[root src]# cd /usr/local/src tar xzf /tmp/analog-5.32.tar.gz cd analog-5.32 make cd .. mv analog-5.32 /usr/share/
See also the section called âSet up Log Analysis Reportsâ
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
A major goal in OpenACS 4 is to unify and normalize many of the core services of the system into a coherent common data model and API. In the past, these services were provided to applications in an ad-hoc and irregular fashion. Examples of such services include:
General Comments
User/groups
Attribute storage in user/groups
General Permissions
Site wide search
General Auditing
All of these services involve relating extra information and services to application data objects, examples of which include:
Bboard messages
A user home page
A ticket in the Ticket Tracker
A photograph in the PhotoDB
In the past, developers had to use ad-hoc and inconsistent schemes to interface to the various "general" services mentioned above. Since each service used its own scheme for storing its metadata and mapping this data to application objects, we could not implement any kind of centralized management system or consistent administrative pages for all the services. Consequently, a large amount of duplicate code appeared throughout the system for dealing with these services.
Unifying and "normalizing" these interfaces, to minimize the amount of code repetition in applications, is a primary goal of OpenACS 4. Thus the Object Model (OM, also referred to later as the object system) is concerned primarily with the storage and management of metadata, on any object within a given instance of OpenACS 4. The term "metadata" refers to any extra data the OM stores on behalf of the application - outside of the application's data model - in order to enable certain generic services. The term "object" refers to any entity being represented within the OpenACS, and typically corresponds to a single row within the relational database.
The OpenACS 4 Object Model must address five high-level requirements that repeatedly exhibit themselves in the context of existing services in OpenACS 3.x, as described below.
Object Identifiers for General Services
Generic services require a single unambiguous way of identifying application objects that they manage or manipulate. In OpenACS 3.x, there are several different idioms that construct object identifiers from other data. Many modules use a (user_id, group_id, scope) triple combination for the purpose of recording ownership information on objects for access control. User/groups also uses (user_id, group_id) pairs in its user_group_map table as a way to identify data associated with a single membership relation.
Also in OpenACS 3.x, many utility modules exist that do nothing more than attach some extra attributes to existing application data. For example, general comments maintains a mapping table that maps application "page" data (static or dynamic) to one or more user comments on the page, by constructing a unique identifier for each page. This identifier is usually a combination of the table in which the data is stored, and the value of the primary key value for the particular page. This idiom is referred to as the "(on_which_table + on_what_id)" method for identifying application data. General comments stores its map from pages to comments using a "(on_which_table + on_what_id)" key, plus the id of the comment itself.
All of these composite key constructions are implicit object identifiers: they build a unique ID out of other pieces of the data model. The problem is that their definition and use is ad-hoc and inconsistent. This makes the construction of generic application-independent services difficult. Therefore, the OpenACS 4 Object Model should provide a centralized and uniform mechanism for tagging application objects with unique identifiers.
Support for Unified Access Control
Access control should be as transparent as possible to the application developer. Until the implementation of the general permissions system, every OpenACS application had to manage access control to its data separately. Later on, a notion of "scoping" was introduced into the core data model.
"Scope" is a term best explained by example. Consider some hypothetical rows in the address_book table:
| ... | scope |
user_id |
group_id |
... |
| ... | user |
123 |
... | |
| ... | group |
456 |
... | |
| ... | public |
... |
The first row represents an entry in User 123's personal address book, the second row represents an entry in User Group 456's shared address book, and the third row represents an entry in the site's public address book.
In this way, the scoping columns identify the security context in which a given object belongs, where each context is either a person or a group of people or the general public (itself a group of people).
The problem with this scheme is that we are limited to using only users and groups as scopes for access control, limiting applications to a single level of hierarchy. Worse, the scoping system demanded that every page needing access to a given application had to do an explicit scope check to make sure access was allowed - if a developer was careless on just one site page, a security problem could result.
Thus the OpenACS 4 Object Model must support a more general access control system that allows access control domains to be hierarchical, and specifiable with a single piece of data, instead of the old composite keys described above.
Extensible Data Models
Another problem with previous OpenACS data models is that many of the central tables in the system became bloated as they were extended to support an increasing number of modules. The users table is the best case in point: it became full of columns that exist for various special applications (e.g. user portraits), but that aren't really related to each other in any way except that they store information on users, i.e. the table became grossly denormalized. Normalizing (breaking-down) this table into several pieces, each of which is specific to a particular application, would improve maintainability greatly. Furthermore, the ability to allow applications or users to define new extensions to existing tables, and have some central metadata facility for keeping track of what data belong to which tables, would be very useful.
Thus the motivation for providing object types and subtyping in the OpenACS 4 Object Model. The OM should allow developers to define a hierarchy of metadata object types with subtyping and inheritance. Developers can then use the framework to allow users to define custom extensions to the existing data models, and the OM does the bookkeeping necessary to make this easier, providing a generic API for object creation that automatically keeps track of the location and relationships between data.
Design Note: While this doesn't really belong in a requirements document, the fact that we are constrained to using relational databases means that certain constraints on the overall design of the object data model exist, which you can read about in Summary and Design Considerations.
Modifiable Data Models
Another recurring applications problem is how to store a modifiable data model, or how to store information that may change extensively between releases or in different client installations. Furthermore, we want to avoid changes to an application's database queries in the face of any custom extensions, since such changes are difficult or dangerous to make at runtime, and can make updating the system difficult. Some example applications in OpenACS 3.x with modifiable data models include:
User/groups: developers and users can attach custom data to group types, groups, and members of groups.
In the Ecommerce data model, the ec_custom_product_fields table defines attributes for catalog products, and the ec_custom_product_field_values table stores values for those attributes.
In the PhotoDB data model, the ph_custom_photo_fields table defines attributes for the photographs owned by a specific user, and tables named according to the convention "ph_user_<user_id>_custom_info" are used to store values for those attributes.
Thus the Object Model must provide a general mechanism for applications and developers to modify or extend data models, without requiring changes to the SQL schema of the system. This ensures that all applications use the same base schema, resulting in a uniform and more maintainable system.
Generic Relations
Many OpenACS applications define simple relationships between application objects, and tag those relationships with extra data. In OpenACS 3.x, this was done using mapping tables. The user/groups module has the most highly developed data model for this purpose, using a single table called user_group_map that mapped users to groups. In addition, it uses the the user_group_member_fields and user_group_member_fields_map tables to allow developers to attach custom attributes to group members. In fact, these custom attributes were not really attached to the users, but to the fact that a user was a member of a particular group - a subtle but important distinction. As a historical note, in OpenACS 3.x, user/groups was the only part of the system that provided this kind of data model in a reusable way. Therefore, applications that needed this capability often hooked into user/groups for no other reason than to use this part of its data model.
The OpenACS 4 data model must support generic relations by allowing developers to define a special kind of object type called a relation type. Relation types are themselves object types that do nothing but represent relations. They can be used by applications that previously used user/groups for the same purpose, but without the extraneous, artificial dependencies.
The Object Model package is a combination of data model and a procedural API for manipulating application objects within an OpenACS instance. The OM allows developers to describe a hierarchical system of object types that store metadata on application objects. The object type system supports subtyping with inheritance, so new object types can be defined in terms of existing object types.
The OM data model forms the main part of the OpenACS 4 Kernel data model. The other parts of the Kernel data model include:
Parties and Groups
Permissions
Each of these is documented elsewhere at length.
(Pending as of 8/27/00)
The data model for the object system provides support for the following kinds of schema patterns that are used by many existing OpenACS modules:
Object identification is a central mechanism in the new metadata system. The fact that every object has a known unique identifier means that the core can deal with all objects in a generic way. Thus the only action required of an application to obtain any general service is to "hook into" the object system.
In OpenACS 3.x, modules use ad-hoc means to construct unique identifiers for objects that they manage. Generally, these unique IDs are built from other IDs that happen to be in the data model. Because there is no consistency in these implementations, every application must hook into every service separately.
Examples of utilities that do this in OpenACS 3.x system are:
User/groups: Information is attached to group membership relations.
General Comments: Comments are attached to objects representing some kind of document.
General Permissions: Stores access control information on application data.
User Profiling: Maps users to pieces of content that they have looked at; content identifiers must be managed in a uniform way.
Site Wide Search: Stores all content in a single flat table, with object identifiers pointing to the object containing the content in the first place. This way, we can search the contents of many different types of objects in a uniform way.
The OM will support and unify this programming idiom by providing objects with unique identifiers (unique within a given OpenACS instance) and with information about where the application data associated with the object is stored. The identifier can be used to refer to collections of heterogeneous application data. More importantly, object identifiers will enable developers to readily build and use generic services that work globally across a system.
The object identifiers should be subject to the following requirements:
10.10 Uniqueness
The object ID should be unique among all the IDs in the entire OpenACS system in which the object lives.
10.20 Useful as a Reference
Applications should be able to use the unique object ID as a reference, with which they can fetch any or all of the object's attributes.
10.30 Storable
Object IDs should be storable in tables. e.g. you should be able to use them to implement mapping tables between objects, to represent relationships.
10.40 Moveable
Objects should be mobile between databases. That is, information will often need to be moved between multiple servers (development, staging, and production), so a mechanism for moving this data is necessary. In addition, a mechanism for tagging these objects in a way similar to CVS would be useful in determining which objects need to be synchronized.
An object type refers to a specification of one or more attributes to be managed along with a piece of application data.
The object system should provide a data model for describing and representing object types. This data model is somewhat analogous to the Oracle data dictionary, which stores information about all user defined tables in the system.
The canonical example of this kind of data model occurs in the current OpenACS 3.x user/groups module, which allows the developer to create new group types that can contain not only generic system level attributes but also extended, developer-defined attributes. In addition, these attributes can either be attached to the group type itself, and shared by all instances, or they can be different for each instance. At its core, the OpenACS 4 object system is meant to be a generalization of this mechanism. The data model should allow developers to at least do everything they used to with user/groups, but without its administrative hassles.
Therefore, the data model must be able to represent object types that have the following characteristics:
20.10 Type Name
A human readable name for the object type.
20.20 Type Attributes
Attributes whose values are shared by all instances of the object type.
20.30 Object Attributes
Attributes that are specific to each particular object belonging to a given type.
The data model must also enforce certain constraints on object types:
20.40 Type Uniqueness
Object type names must be unique.
20.50 Attribute Name Uniqueness
Attribute names must be unique in the scope of a single object type and any of its parent types.
The Object Model must support the definition of object types that are subtypes of existing types. A subtype inherits all the attributes of its parent type, and defines some attributes of its own. A critical aspect of the OM is parent types may be altered, and any such change must propagate to child subtypes.
The OM data model must enforce constraints on subtypes that are similar to the ones on general object types.
30.10 Subtype Uniqueness
Subtype names must be unique (this parallels requirement 10.40).
30.20 Subtype Attribute Name Uniqueness
Attribute names must be unique in the scope of a single object subtype.
30.30 Parent Type Prerequisite
Subtypes must be defined in terms of parent types that, in fact, already exist.
30.40
The extended attribute names in a subtype must not be the same as those in its parent type.
35.10 Method and Type Association
The OM data model should define a mechanism for associating procedural code, called methods, with objects of a given type. Methods are associated with the each object type - not each object instance.
35.20 Method Sharing
All instances of a given object type should share the same set of defined methods for that type.
In addition to information on types, the OM data model provides for the centralized storage of object attribute values. This facility unifies the many ad-hoc attribute/value tables that exist in various OpenACS 3.x data models, such as:
User groups: Each instance of a group type can have custom data.
Photo DB: Users can define their own custom metadata to attach to photograph objects.
Ecommerce: Vendors can attach custom fields to the data model describing their products.
40.10 Generic Retrieval
Attributes should be stored so that they are retrievable in a way that is independent of the type of the object that they belong to. That is, the only data needed to retrieve an attribute should be the system-wide ID of an object (see requirement 10.20 above) and the attribute name.
40.20 Inherited Attributes
The system should allow for the automatic retrieval of inherited attribute values, for an object belonging to a subtype.
40.30. Constraints on Attributes
The system should allow the developer to put down constraints on the values that an attribute may hold, for the purposes of maintaining application specific integrity rules.
In OpenACS 3.x, there was a notion of "scope" for application objects. An object could be belong to one of three scopes: public, group or user. This provided a crude way to associate objects with particular scopes in the system, but it was awkward to use and limited in flexibility.
The OpenACS 4 Object Model provides a generalized notion of scope that allows developers to represent a hierarchy of object contexts. These contexts are used as the basis for the permissions system. In general, if an object has no explicit permissions attached to it, then it inherits permissions from its context.
The context data model also forms the basis of the subsites system, and is a basic part of the permissions system, described in separate documents.
The context data model should provide the following facilities:
50.10 Unique ID
Every context should have a unique ID in the system.
50.20 Tree Structure
The data model should support a tree structured organization of contexts. That is, contexts can be logically "contained" within other contexts (i.e. contexts have parents) and contexts can contain other contexts (i.e. contexts can have children).
50.30 Data Model Constraints
All objects must have a context ID. This ID must refer to an existing context or be NULL. The meaning of a NULL context is determined by the implementation.
Note:
The current system interprets the NULL context as meaning the default "site-wide" context in some sense. I wanted to note this fact for others, but there is no need to make this a requirement of the system. I think it would be reasonable to have a NULL context be an error (psu 8/24/2000).
The data model should include a notion of pair-wise relations between objects. Relations should be able to record simple facts of the form "object X is related to object Y by relationship R," and also be able to attach attributes to these facts.
The API should let programmers accomplish the following actions:
60.10 Create a New Object Type
The object system API should provide a procedure call that creates a new object type by running the appropriate transactions on the object system data model. This API call is subject to the constraints laid out in the data model. We call this operation "instantiating" an object.
60.20 Create a New Object Subtype
The object system API should provide a procedure call for creating subtypes of a given type. Operationally, this API is the same as requirement 60.10. Instances of subtypes automatically contain all attributes of the parent type in addition to all attributes of the subtype. This API is subject to the constraints laid out in the data model.
60.30 Create a New Relation Type
There should be an API call to create a new type of object relation. Relation types can be modeled as object types. The API below for manipulating attributes can then be used to add attributes to relation types.
The object system API must allow the programmer to modify, add, and delete attributes from any object type. Updates should be propagated to any child subtypes. This API is subject to the constraints laid out in the data model.
The system provides an API call for deleting an object type.
80.10
Deleting an object type destroys all instances of the type. It should be an error to delete types that have dependent subtypes. This API is subject to the constraints laid out in the data model.
80.10.10
However, the programmer should also be able to specify that all the subtypes and instances of those subtypes be destroyed before destroying the object type. This is similar to a "delete cascade" constraint in SQL.
The system must provide API calls to manage the creation and destruction of object instances.
90.10 Create an Instance of an Object Type
The system should provide an API call for creating a new instance of a given object type. The new instance should be populated with values for each of the attributes specified in the definition of the type. In addition, it should be possible to create the new instance with an optional context ID that refers to the default context that the object will live in.
90.20 Delete an Object Instance
The OM should provide an API call for object deletion. Objects can be deleted only when no other objects in the system refer to them. Since it might not be practical to provide a mechanism like "delete cascade" here in a reliable way, providing such a facility in the system is optional.
The system must provide API calls to manage the creation and destruction of object relations.
The OM must provide an API call to declare that two objects are related to each other by a given relation type. This API call should also allow programmers to attach attributes to this object relation.
There should be an API call for destroying object relations and their attributes.
The system should provide an API to create and destroy object contexts.
The system should provide an API for updating the attribute values of a particular instance of an object type.
The system should provide an API for retrieving attribute values from a particular instance of an object type.
The Object Model must support the efficient storage and retrieval of object attributes. Since the OM is intended to form the core of many general services in the OpenACS, and these services will likely make extensive use of the OM tables, queries on these tables must be fast. The major problem here seems to be supporting subtyping and inheritance in a way that does not severely impact query performance.
Most OpenACS packages will be expected to use the Object Model in one way or another. Since it is important that the largest audience of developers possible adopts and uses the OM, it must be easy to incorporate into applications, and it must not impose undue requirements on an application's data model. In other words, it should be easy to "hook into" the object model, and that ability should not have a major impact on the application data model.
Note: Is the API the only way to obtain values? How does this integrate with application level SQL queries?
| Document Revision # | Action Taken, Notes | When? | By Whom? |
| 0.1 | Creation | 08/10/2000 | Bryan Quinn |
| 0.2 | Major re-write | 08/11/2000 | Pete Su |
| 0.3 | Draft completed after initial reviews | 08/22/2000 | Pete Su |
| 0.4 | Edited, updated to conform to requirements template, pending freeze | 08/23/2000 | Kai Wu |
| Final edits before freeze | 08/24/2000 | Pete Su | |
| 0.5 | Edited for consistency | 08/27/2000 | Kai Wu |
| 0.6 | Put Object ID stuff first, because it makes more sense | 08/28/2000 | Pete Su |
| 0.7 | Added requirement that knowledge-level objects must be moveable between databases. | 08/29/2000 | Richard Li |
| 0.8 | Rewrote intro to match language and concepts in the design document. Also cleaned up usage a bit in the requirements section. Added short vague requirements on relation types. | 09/06/2000 | Pete Su |
| 0.9 | Edited for ACS 4 Beta release. | 09/30/2000 | Kai Wu |
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
Almost all database-backed websites have users, and need to model the grouping of users. The OpenACS 4 Parties and Groups system is intended to provide the flexibility needed to model complex real-world organizational structures, particularly to support powerful subsite services; that is, where one OpenACS installation can support what appears to the user as distinct web services for different user communities.
A powerful web service that can meet the needs of large enterprises must be able to model the the real world's very rich organizational structures and many ways of decomposing the same organization. For example, a corporation can be broken into structures (the corporation, its divisions, and their departments) or regions (the Boston office, the LA office); a person who is employed by (is a member of) a specific department is also a member of the division and the corporation, and works at (is a member of, but in a different sense) a particular office. OpenACS's Parties and Groups system will support such complex relations faithfully.
Historical Motivations
The primary limitation of the OpenACS 3.x user group system is that it restricts the application developer to representing a "flat group" that contains only users: The user_groups table may contain the group_id of a parent group, but parent-child relationship support is limited because it only allows one kind of relationship between groups to be represented. Moreover, the Oracle database's limited support for tree-like structures makes the queries over these relationships expensive.
In addition, the Module Scoping design in OpenACS 3.0 introduced a party abstraction - a thing that is a person or a group of people - though not in the form of an explicit table. Rather, the triple of scope, user_id, and group_id columns was used to identify the party. One disadvantage of this design convention is that it increases a data model's complexity by requiring the programmer to:
add these three columns to each "scoped" table
define a multi-column check constraint to protect against data corruption (e.g., a row with a scope value of "group" but a null group_id)
perform extra checks in Tcl and PL/SQL functions and procedures to check both the user_id and group_id values
In sum, the goal of the Parties and Groups system is to provide OpenACS programmers and site administrators with simple tools that fully describe the complex relationships that exist among groups in the real world.
Pat Developer has a client project and wants to model the company, its offices, its divisions, and its departments as groups and the employees as users.
We start with Groups, which contain members; the member can be either a person or another group (i.e. a member is a party).
In addition to membership, the party and groups system defines a composition relationship that may exist between groups: A group can be a component of another group. The child group is called a component group; the parent group is called a composite group.
A group Gc can be a member and/or a component of another group Gp ; the difference is in the way the members of Gc are related to Gp :
If a party P is a member (or a component) of Gc and if Gc is a component of Gp , then P is also a member (or a component) of Gp
If a party P is a member (or a component) of Gc and if Gc is a member of Gp , then no relationship between P and Gp exists as a result of the relationship between Gp and Gp .
Consider an example to make this less abstract: Pretend that the Sierra Club is a member of Greenpeace. The Sierra Club has chapters; each chapter is a component of the Sierra Club. If Eddie Environmentalist is a member of the Massachusetts Chapter of the Sierra Club, Eddie is automatically a member of the Sierra Club, but being a Sierra Club member does not make Eddie a member of Greenpeace.
In the OpenACS, Greenpeace, Sierra Club, and the Sierra Club chapters would be modeled as groups, and Eddie would be a user. There would be a composition relationship between each Sierra Club chapter and the Sierra Club. Membership relationships would exist between Eddie and the Massachusetts Chapter, between Eddie and the Sierra Club (due to Eddie's membership in the Massachusetts chapter), and between the Sierra Club and Greenpeace.
Membership requirements can vary from group to group. The parties and groups system must provide a base type that specifies the bare minimum necessary to join a group.
The parties and groups system must support constraints between a composite group GP and any of its component groups, GC . For example, the system should be able to enforce a rule like: Do not allow a party P to become a member of GC unless P is already a member of GP .
The data model for the parties and groups system must provide support for the following types of entities:
A party is an entity used to represent either a group or a person.
The data model should enforce these constraints:
10.10 A party has an email address, which can be empty.
10.20 A party may have multiple email addresses associated with it.
10.30 The email address of a party must be unique within an OpenACS system.
A group is a collection of zero or more parties.
20.10 The data model should support the subclassing of groups via OpenACS Objects.
A person represents an actual human being, past or present.
A user is a person who has registered with an OpenACS site. A user may have additional attributes, such as a screen name.
The data model should enforce these constraints:
40.10 A user must have a non-empty email address.
40.20 Two different users may not have the same email address on a single OpenACS installation; i.e., an email address identifies a single user on the system.
40.30 A user may have multiple email addresses; for example, two or more email addresses may identify a single user.
40.40 A user must have password field which can be empty.
The data model for the parties and groups system must provide support for the following types of relationships between entities:
A party P is considered a member of a group G
when a direct membership relationship exists between P and G
or when there exists a direct membership relationship between P and some group GC and GC has a composition relationship (c.f., 60.0) with G.
50.10 A party may be a member of multiple groups.
50.20 A party may be a member of the same group multiple times only when all the memberships have different types; for example, Jane may be a member of The Company by being both an Employee and an Executive.
50.30 A party as a member of itself is not supported.
50.40 The data model must support membership constraints.
50.50The data model should support the subclassing of membership via OpenACS Relationships.
A group GC is considered a component of a second group GP
when a direct composition relationship exists between GC and GP
or when there exists a direct composition relationship between GC and some group Gi and Gi has a composition relationship with GP .
60.10A group may be a component of multiple groups.
60.20A group as a component of itself is not supported.
60.30The data model must support component constraints.
60.40The data model should support the subclassing of composition via OpenACS Relationships.
The API should let programmers accomplish the following tasks:
The parties and groups system provides a well defined API call that creates a new group by running the appropriate transactions on the parties and groups system data model. This API is subject to the constraints laid out in the data model.
The parties and groups system provides a well defined API call that creates a new person by running the appropriate transactions on the parties and groups system data model. This API is subject to the constraints laid out in the data model.
The parties and groups system provides a well defined API call that creates a new user by running the appropriate transactions on the parties and groups system data model. This API is subject to the constraints laid out in the data model.
The parties and groups system provides a well defined API call that creates a new user by running the appropriate transactions on an existing person entity. This API is subject to the constraints laid out in the data model.
The parties and groups system provides a well defined API call that demotes an existing user entity to a person entity by running the appropriate transactions on the existing user. This API is subject to the constraints laid out in the data model.
The programmer should be able to modify, add, and delete attributes on any party. This API is subject to the constraints laid out in the data model.
The programmer should be able to view the attributes on any party. This API is subject to the constraints laid out in the data model.
The system provides an API for deleting a party. This API is subject to the constraints laid out in the data model.
100.30 The system may provide a single API call to remove the party from all groups and then delete the party.
100.40 In the case of a group, the system may provide a single API call to remove all parties from a group and then delete the group.
The parties and groups system provides an API for adding a party as a member of a group. This API is subject to the constraints laid out in the data model.
The parties and groups system provides an API for adding a group as a component of a second group. This API is subject to the constraints laid out in the data model.
The parties and groups system provides an API for deleting a party's membership in a group. This API is subject to the constraints laid out in the data model.
The parties and groups system provides an API for deleting a group's composition in a second group. This API is subject to the constraints laid out in the data model.
The parties and groups system provides an API for answering the question: "Is party P a member of group G?"
The parties and groups system provides an API for answering the question: "Is group GC a component of group GP ?"
The parties and groups system provides an API for answering the question: "Which parties are members of group G?"
The parties and groups system provides an API for answering the question: "Which groups are components of group G?"
The parties and groups system provides an API for answering the question: "Of which groups is party P a member?"
The parties and groups system provides an API for answering the question: "Of which groups is group G a component?"
The parties and groups system provides an API for answering the question: "Is party P allowed to become a member of group G?"
The parties and groups system provides an API for answering the question: "Is group GC allowed to become a component of group GP ?"
Since many pages at a site may check membership in a group before serving a page (e.g., as part of a general permissions check), the data model must support the efficient storage and retrieval of party attributes and membership.
Since many SQL queries will check membership in a group as part of the where clause, whatever mechanism is used to check membership in SQL should be fairly small and simple.
The user interface is a set of HTML pages that are used to drive the underlying API. The user interface may provide the following functions:
200.0 Create a party
210.0 View the attributes of a party
220.0 Update the attributes of a party
240.0 Delete a party
250.0 Add a party to a group
260.0 Remove a party from a group
270.0 Perform the membership and composition checks outlined in 130.x to 165.x
| Document Revision # | Action Taken, Notes | When? | By Whom? |
| 0.1 | Creation | 08/16/2000 | Rafael Schloming |
| 0.2 | Initial revision | 08/19/2000 | Mark Thomas |
| 0.3 | Edited and reviewed, conforms to requirements template | 08/23/2000 | Kai Wu |
| 0.4 | Further revised, added UI requirements | 08/24/2000 | Mark Thomas |
| 0.5 | Final edits, pending freeze | 08/24/2000 | Kai Wu |
| 0.6 | More revisions, added composition requirements | 08/30/2000 | Mark Thomas |
| 0.7 | More revisions, added composition requirements | 09/08/2000 | Mark Thomas |
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
While many applications must deal with individuals and many applications must deal with groups, most applications must deal with individuals or groups. It is often the case with such applications that both individuals and groups are treated identically. Modelling individuals and groups as specializations of one supertype is a practical way to manage both. This concept is so mundane that there is no need to invent special terminology. This supertype is called a "party".
A classic example of the "party" supertype is evident in address books. A typical address book might contain the address of a doctor, grocery store, and friend. The first field in an entry in the address book is not labeled a person or company, but a "party".
The parties developer guide begins with an introduction to the parties data model, since OpenACS community applications likely require using it in some way.
Parties
The central table in the parties data model is the parties table itself. Every party has exactly one row in this table. Every party has an optional unique email address and an optional url. A party is an acs object, so permissions may be granted and revoked on parties and auditing information is stored in the acs objects table.
create table parties (
party_id not null
constraint parties_party_id_fk references
acs_objects (object_id)
constraint parties_party_id_pk primary key,
email varchar(100)
constraint parties_email_un unique,
url varchar(200)
);
The persons and groups tables extend the parties table. A row in the persons table represents the most generic form of individual modeled. An individual need not be known to the system as a user. A user is a further specialized form of an individual (discussed later). A row in the groups table represents the most generic form of group modeled, where a group is an aggregation of zero or more individuals.
Persons
If a party is an individual then there will be a row in the persons table containing first_names and last_name for that individual. The primary key of the persons table (person_id) references the primary key of the parties table (party_id), so that there is a corresponding row in the parties table when there is a row in the persons table.
create table persons (
person_id not null
constraint persons_person_id_fk
references parties (party_id)
constraint persons_person_id_pk primary key,
first_names varchar(100) not null,
last_name varchar(100) not null
);
Users
The users table is a more specialized form of persons table. A row in users table represents an individual that has login access to the system. The primary key of the users table references the primary key of the persons table. This guarantees that if there is a row in users table then there must be a corresponding row in persons and parties tables.
Decomposing all the information associated with a user into the four tables (acs_objects, parties, persons, users) has some immediate benefits. For instance, it is possible to remove access to a user from a live system by removing his entry from the users table, while leaving the rest of his information present (i.e. turning him from a user into a person).
Wherever possible the OpenACS data model references the persons or parties table, not the users table. Developers should be careful to only reference the users table in situations where it is clear that the reference is to a user for all cases and not to any other individual for any case.
create table users (
user_id not null
constraint users_user_id_fk
references persons (person_id)
constraint users_user_id_pk primary key,
password varchar(100),
salt varchar(100),
screen_name varchar(100)
constraint users_screen_name_un
unique,
priv_name integer default 0 not null,
priv_email integer default 5 not null,
email_verified_p char(1) default 't'
constraint users_email_verified_p_ck
check (email_verified_p in ('t', 'f')),
email_bouncing_p char(1) default 'f' not null
constraint users_email_bouncing_p_ck
check (email_bouncing_p in ('t','f')),
no_alerts_until date,
last_visit date,
second_to_last_visit date,
n_sessions integer default 1 not null,
password_question varchar(1000),
password_answer varchar(1000)
);
Groups
The final piece of the parties data model is the groups data model. A group is a specialization of a party that represents an aggregation of zero or more other parties. The only extra information directly associated with a group (beyond that in the parties table) is the name of the group:
create table groups (
group_id not null
constraint groups_group_id_fk
references parties (party_id)
constraint groups_group_id_pk primary key,
group_name varchar(100) not null
);
There is another piece to the groups data model that records relations between parties and groups.
Group Relations
Two types of group relations are represented in the data model: membership relations and composite relations. The full range of sophisticated group structures that exist in the real world can be modelled in OpenACS by these two relationship types.
Membership relations represent direct membership relation between parties and groups. A party may be a "member" of a group. Direct membership relations are common in administrative practices, and do not follow basic set theory rules. If A is a member of B, and B is a member of C, A is not a member of C. Membership relations are not transitive.
Composition relation represents composite relation between two groups. Composite relation is transitive. That is, it works like memberships in set theory. If A is a member of B, and B is a member of C, then A is a member of C.
For example, consider the membership relations of Greenpeace, and composite relations of a multinational corporation. Greenpeace, an organization (ie. group), can have both individuals and organizations (other groups) as members. Hence the membership relation between groups and parties. However, someone is not a member of Greenpeace just because they are a member of a group that is a member of Greenpeace. Now, consider a multinational corporation (MC) that has a U.S. division and a Eurasian division. A member of either the U.S. or Eurasian division is automatically a member of the MC. In this situation the U.S. and Eurasian divisions are "components" of the MC, i.e., membership is transitive with respect to composition. Furthermore, a member of a European (or other) office of the MC is automatically a member of the MC.
Group Membership
Group memberships can be created and manipulated using the membership_rel package. Only one membership object can be created for a given group, party pair.
It is possible in some circumstances to make someone a member of a group of which they are already a member. That is because the model distinguishes between direct membership and indirect membership (membership via some composite relationship). For example, a person might be listed in a system as both an individual (direct membership) and a member of a household (indirect membership) at a video rental store.
# sql code
create or replace package membership_rel
as
function new (
rel_id in membership_rels.rel_id%TYPE default null,
rel_type in acs_rels.rel_type%TYPE default 'membership_rel',
object_id_one in acs_rels.object_id_one%TYPE,
object_id_two in acs_rels.object_id_two%TYPE,
member_state in membership_rels.member_state%TYPE default null,
creation_user in acs_objects.creation_user%TYPE default null,
creation_ip in acs_objects.creation_ip%TYPE default null
) return membership_rels.rel_id%TYPE;
procedure ban (
rel_id in membership_rels.rel_id%TYPE
);
procedure approve (
rel_id in membership_rels.rel_id%TYPE
);
procedure reject (
rel_id in membership_rels.rel_id%TYPE
);
procedure unapprove (
rel_id in membership_rels.rel_id%TYPE
);
procedure deleted (
rel_id in membership_rels.rel_id%TYPE
);
procedure delete (
rel_id in membership_rels.rel_id%TYPE
);
end membership_rel;
/
show errors
Group Composition
Composition relations can be created or destroyed using the composition_rel package. The only restriction on compositions is that there cannot be a reference loop, i.e., a group cannot be a component of itself either directly or indirectly. This constraint is maintained for you by the API. So users do not see some random PL/SQL error message, do not give them the option to create a composition relation that would result in a circular reference.
# sql code
create or replace package composition_rel
as
function new (
rel_id in composition_rels.rel_id%TYPE default null,
rel_type in acs_rels.rel_type%TYPE default 'composition_rel',
object_id_one in acs_rels.object_id_one%TYPE,
object_id_two in acs_rels.object_id_two%TYPE,
creation_user in acs_objects.creation_user%TYPE default null,
creation_ip in acs_objects.creation_ip%TYPE default null
) return composition_rels.rel_id%TYPE;
procedure delete (
rel_id in composition_rels.rel_id%TYPE
);
end composition_rel;
/
show errors
The parties data model does a reasonable job of representing many of the situations one is likely to encounter when modeling organizational structures. We still need to be able to efficiently answer questions like "what members are in this group and all of its components?", and "of what groups is this party a member either directly or indirectly?". Composition relations allow you to describe an arbitrary Directed Acyclic Graph (DAG) between a group and its components. For these reasons the party system provides a bunch of views that take advantage of the internal representation of group relations to answer questions like these very quickly.
The group_component_map view returns all the subcomponents of a group including components of sub components and so forth. The container_id column is the group_id of the group in which component_id is directly contained. This allows you to easily distinguish whether a component is a direct component or an indirect component. If a component is a direct component then group_id will be equal to container_id. You can think of this view as having a primary key of group_id, component_id, and container_id. The rel_id column points to the row in acs_rels table that contains the relation object that relates component_id to container_id. The rel_id might be useful for retrieving or updating standard auditing info for the relation.
create or replace view group_component_map
as select group_id, component_id, container_id, rel_id
...
The group_member_map view is similar to group_component_map except for membership relations. This view returns all membership relations regardless of membership state.
create or replace view group_member_map
as select group_id, member_id, container_id, rel_id
...
The group_approved_member_map view is the same as group_member_map except it only returns entries that relate to approved members.
create or replace view group_approved_member_map
as select group_id, member_id, container_id, rel_id
...
The group_distinct_member_map view is a useful view if you do not care about the distinction between direct membership and indirect membership. It returns all members of a group including members of components --the transitive closure.
create or replace view group_distinct_member_map
as select group_id, member_id
...
The party_member_map view is the same as group_distinct_member_map, except it includes the identity mapping. It maps from a party to the fully expanded list of parties represented by that party including the party itself. So if a party is an individual, this view will have exactly one mapping that is from that party to itself. If a view is a group containing three individuals, this view will have four rows for that party, one for each member, and one from the party to itself.
create or replace view party_member_map
as select party_id, member_id
...
The party_approved_member_map view is the same as party_member_map except that when it expands groups, it only pays attention to approved members.
create or replace view party_approved_member_map
as select party_id, member_id
...
The parties data model can represent some fairly sophisticated real world situations. Still, it would be foolish to assume that this data model is sufficiently efficient for every application. This section describes some of the more common ways to extend the parties data model.
Specializing Users
Some applications will want to collect more detailed information for people using the system. If there can be only one such piece of information per user, then it might make sense to create another type of individual that is a further specialization of a user. For example a Chess Club community web site might want to record the most recent score for each user. In a situation like this it would be appropriate to create a subtype of users, say chess_club_users. This child table of the users table would have a primary key that references the users table, thereby guaranteeing that each row in the chess_club_users table has a corresponding row in each of the users, persons, parties, and acs_objects tables. This child table could then store any extra information relevant to the Chess Club community.
Specializing Groups
If one were to build an intranet application on top of the party system, it is likely that one would want to take advantage of the systems efficient representation of sophisticated organizational structures, but there would be much more specialized information associated with each group. In this case it would make sense to specialize the group party type into a company party type in the same manner as Specializing Users.
Specializing Membership Relations
The final portion of the parties data model that is designed to be extended is the membership relationship. Consider the intranet example again. It is likely that a membership in a company would have more information associated with it than a membership in an ordinary group. An obvious example of this would be a salary. It is exactly this need to be able to extend membership relations with mutable pieces of state that drove us to include a single integer primary key in what could be thought of as a pure relation. Because a membership relation is an ordinary acs object with object identity, it is as easy to extend the membership relation to store extra information as it is to extend the users table or the groups table.
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
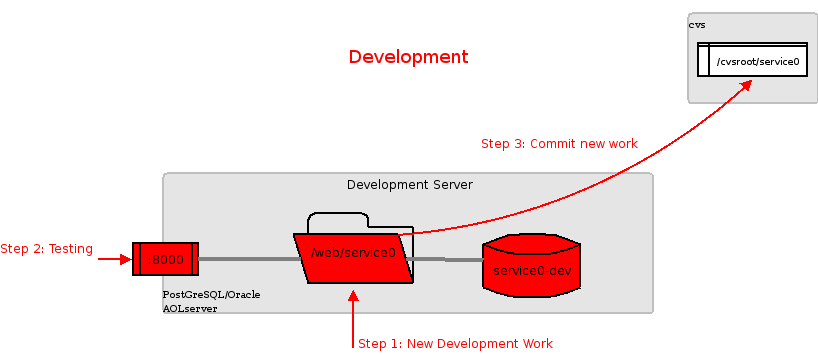
Before you do any more work, make sure that your work is protected by putting it all into cvs. The cvs add command is not recursive, so you'll have to traverse the directory tree manually and add as you go. (More on CVS)
[$OPENACS_SERVICE_NAME xml]$cd ..[$OPENACS_SERVICE_NAME doc]$cd ..[$OPENACS_SERVICE_NAME www]$cd ..[$OPENACS_SERVICE_NAME myfirstpackage]$cd ..[$OPENACS_SERVICE_NAME packages]$cvs add myfirstpackage/Directory /cvsroot/$OPENACS_SERVICE_NAME/packages/myfirstpackage added to the repository [$OPENACS_SERVICE_NAME packages]$cd myfirstpackage/[$OPENACS_SERVICE_NAME myfirstpackage]$cvs add wwwDirectory /cvsroot/$OPENACS_SERVICE_NAME/packages/myfirstpackage/www added to the repository [$OPENACS_SERVICE_NAME myfirstpackage]$cd www[$OPENACS_SERVICE_NAME www]$cvs add docDirectory /cvsroot/$OPENACS_SERVICE_NAME/packages/myfirstpackage/www/doc added to the repository [$OPENACS_SERVICE_NAME www]$cd doc[$OPENACS_SERVICE_NAME doc]$cvs add *cvs add: cannot add special file `CVS'; skipping cvs add: scheduling file `admin-guide.html' for addition cvs add: scheduling file `bi01.html' for addition cvs add: scheduling file `data-model.dia' for addition cvs add: scheduling file `data-model.png' for addition cvs add: scheduling file `design-config.html' for addition cvs add: scheduling file `design-data-model.html' for addition cvs add: scheduling file `design-future.html' for addition cvs add: scheduling file `design-ui.html' for addition cvs add: scheduling file `filename.html' for addition cvs add: scheduling file `index.html' for addition cvs add: scheduling file `page-map.dia' for addition cvs add: scheduling file `page-map.png' for addition cvs add: scheduling file `requirements-cases.html' for addition cvs add: scheduling file `requirements-introduction.html' for addition cvs add: scheduling file `requirements-overview.html' for addition cvs add: scheduling file `requirements.html' for addition cvs add: scheduling file `sample-data.html' for addition cvs add: scheduling file `sample.png' for addition cvs add: scheduling file `user-guide.html' for addition cvs add: scheduling file `user-interface.dia' for addition cvs add: scheduling file `user-interface.png' for addition Directory /cvsroot/$OPENACS_SERVICE_NAME/packages/myfirstpackage/www/doc/xml added to the repository cvs add: use 'cvs commit' to add these files permanently [$OPENACS_SERVICE_NAME doc]$cd xml[$OPENACS_SERVICE_NAME xml]$cvs add Makefile index.xmlcvs add: scheduling file `Makefile' for addition cvs add: scheduling file `index.xml' for addition cvs add: use 'cvs commit' to add these files permanently [$OPENACS_SERVICE_NAME xml]$cd ../../..[$OPENACS_SERVICE_NAME myfirstpackage]$cvs commit -m "new package"cvs commit: Examining . cvs commit: Examining www cvs commit: Examining www/doc cvs commit: Examining www/doc/xml RCS file: /cvsroot/$OPENACS_SERVICE_NAME/packages/myfirstpackage/www/doc/admin-guide.html,v done Checking in www/doc/admin-guide.html; /cvsroot/$OPENACS_SERVICE_NAME/packages/myfirstpackage/www/doc/admin-guide.html,v <-- admin-guide.html initial revision: 1.1 done (many lines omitted) [$OPENACS_SERVICE_NAME myfirstpackage]$
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
OpenACS has a form manager called ad_form. Ad_form has an adaptable UI. Error handling includes inline error reporting, and is customizable. However, ad_form can be tricky to use. In addition to this document, the ad_form api documentation is helpful.
Some elements have more than one choice, or can submit more than one value.
Creating the form element.Populate a list of lists with values for the option list.
set foo_options [db_list_of_lists foo_option_list "
select foo,
foo_id
from foos
"]
The variable foo_options should resemble {{first foo} 1234} {{second foo} 1235}
Within ad_form, set up the element to use this list:
{foo:text(select)
{label "Which Foo"}
{options $foo_options}
}
This will result in a single name/value pair coming back in the submitted form. Handle this within the same ad_form structure, in the -new_data and -edit_data. In the example, it is available as $foo
See also the W3C spec for "The SELECT, OPTGROUP, and OPTION elements".
A situation you may run into often is where you want to pull in form items from a sub-category when the first category is selected. Ad_form makes this fairly easy to do. In the definition of your form element, include an html section
{pm_task_id:integer(select),optional
{label "Subject"}
{options {$task_options}}
{html {onChange "document.form_name.__refreshing_p.value='1';submit()"}}
{value $pm_task_id}
}
What this will do is set the value for pm_task_id and all the other form elements, and resubmit the form. If you then include a block that extends the form, you'll have the opportunity to add in subcategories:
if {[exists_and_not_null pm_task_id]} {
db_1row get_task_values { }
ad_form -extend -name form_name -form { ... }
Note that you will get strange results when you try to set the values for the form. You'll need to set them explicitly in an -on_refresh section of your ad_form. In that section, you'll get the values from the database, and set the values as so:
db_1row get_task_values { }
template::element set_value form_name estimated_hours_work $estimated_hours_work
A good way to troubleshoot when you're using ad_form is to add the following code at the top of the .tcl page (thanks Jerry Asher):
ns_log notice it's my page!
set mypage [ns_getform]
if {[string equal "" $mypage]} {
ns_log notice no form was submitted on my page
} else {
ns_log notice the following form was submitted on my page
ns_set print $mypage
}
Here are some tips for dealing with some of the form widgets:
Here are some common errors and what to do when you encounter them:
This generally happens when there is an error in your query.
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
This step by step guide is derived from the installation instructions which you can find at yourdomain.com/doc/acs-authentication/ext-auth-pam-install.html. It is build upon PAM 0.77 (tested) and does not work on RedHat Linux Enterprise 3 (using PAM 0.75). It makes use of the ns_pam module written by Mat Kovach. The instructions given in here do work with PAM LDAP accordingly and differences will be shown at the end of the file.
Install ns_pam.Download and install ns_pam
[root aolserver]#cd /usr/local/src/aolserver/[root aolserver]#wget http://braindamage.alal.com/software/ns_pam-0.1.tar.gz[root aolserver]#tar xvfz ns_pam-0.1.tar.gz[root aolserver]#cd ns_pam-0.1[root ns_pam-0.1]#make install INST=/usr/local/aolserver[root ns_pam-0.1]# cd /usr/local/src/aolserver/ wget http://braindamage.alal.com/software/ns_pam-0.1.tar.gz tar xvfz ns_pam-0.1.tar.gz cd ns_pam-0.1 make install INST=/usr/local/aolserver
Configure ns_pam.Configure AOLserver for ns_pam
To enable ns_pam in AOLServer you will first have to edit your config.tcl file and enable the loading of the ns_pam module and configure the aolservers pam configuration file.
Change config.tcl. Remove the # in front of ns_param nspam ${bindir}/nspam.so to enable the loading of the ns_pam module.
Change config.tcl. Replace pam_domain in the section ns/server/${server}/module/nspam with aolserver
Create /etc/pam.d/aolserver.
[root ns_pam]#cp /var/lib/aolserver/service0/packages/acs-core-docs/www/files/pam-aolserver.txt /etc/pam.d/aolserver
Configure PAM Radius.Configure and install PAM Radius
You have to make sure that pam_radius v.1.3.16 or higher is installed, otherwise you will have to install it.
[root ns_pam]#cd /usr/local/src/[root src]#wget ftp://ftp.freeradius.org/pub/radius/pam_radius-1.3.16.tar[root src]#tar xvf pam_radius-1.3.16[root src]#cd pam_radius[root pam_radius]#make[root pam_radius]#cp pam_radius_auth.so /lib/security/[root pam_radius]# cd /usr/local/src wget ftp://ftp.freeradius.org/pub/radius/pam_radius-1.3.16.tar tar xvf pam_radius-1.3.16 cd pam_radius make cp pam_radius_auth.so /lib/security/
Next you have to add the configuration lines to your Radius configuration file (/etc/rddb/server). For AOLserver to be able to access this information you have to change the access rights to this file as well.
[root pam_radius]#echo "radius.yourdomain.com:1645 your_radius_password >>/etc/rddb/server[root src]#chown service0:web /etc/rddb/server
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
To run a database on a different machine than the webserver requires changes to the database configuration file and access control file, and to the OpenACS service's configuration file.
Edit the database configuration file, which in a Reference install is located at /usr/local/pgsql/data/postgresql.conf and change
#tcpip_socket = false
to
tcpip_socket = true
Change the access control file for the database to permit specific remote clients to access. Access can be controlled ... (add notes from forum post)
Change the OpenACS service's configuration file to point to the remote database. Edit /var/lib/aolserver/$OPENACS_SERVICE_NAME/etc/config.tcl and change
to
Created by Gustaf Neumann, last modified by Gustaf Neumann 17 Feb 2008, at 07:08 AM
Did performance problems happen overnight, or did they sneak up on you? Any clue what caused the performance problems (e.g. loading 20K users into .LRN)
Is the file system out of space? Is the machine swapping to disk constantly?
Isolating and solving database problems.
Without daily internal maintenance, most databases slowly degrade in performance. For PostGreSQL, see the section called âVacuum Postgres nightlyâ. For Oracle, use exec dbms_stats.gather_schema_stats('SCHEMA_NAME') (Andrew Piskorski's Oracle notes).
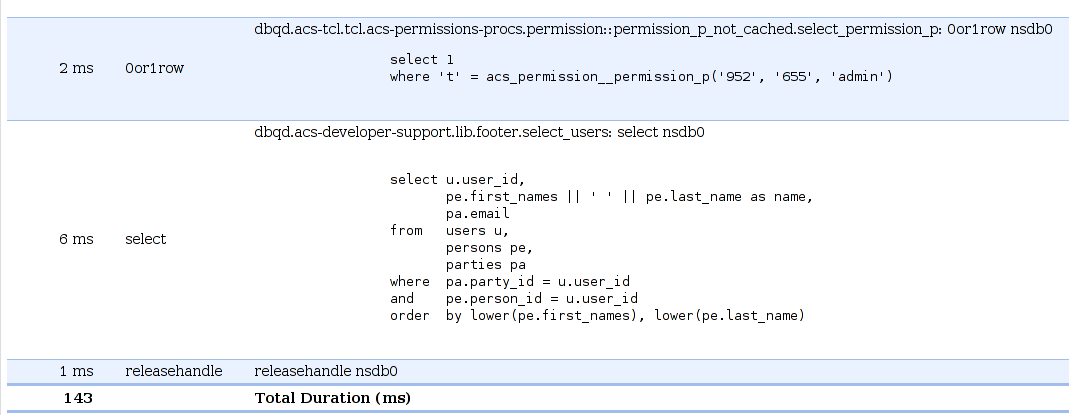
You can track the exact amount of time each database query on a page takes:
Go to Main Site : Site-Wide Administration : Install Software
Click on "Install New Application" in "Install from OpenACS Repository"
Choose "ACS Developer Support">
After install is complete, restart the server.
Browse to Developer Support, which is automatically mounted at /ds.
Turn on Database statistics
Browse directly to a slow page and click "Request Information" at the bottom of the page.
This should return a list of database queries on the page, including the exact query (so it can be cut-paste into psql or oracle) and the time each query took.
Identify a runaway Oracle query: first, use ps aux or top to get the UNIX process ID of a runaway Oracle process.
Log in to SQL*Plus as the admin:
[$OPENACS_SERVICE_NAME ~]$ svrmgrl
Oracle Server Manager Release 3.1.7.0.0 - Production
Copyright (c) 1997, 1999, Oracle Corporation. All Rights Reserved.
Oracle8i Enterprise Edition Release 8.1.7.3.0 - Production
With the Partitioning option
JServer Release 8.1.7.3.0 - Production
SVRMGR> connect internal
Password:
See all of the running queries, and match the UNIX PID:
select p.spid -- The UNIX PID
,s.sid ,s.serial#
,p.username as os_user
,s.username ,s.status
,p.terminal ,p.program
from v$session s ,v$process p
where p.addr = s.paddr
order by s.username ,p.spid ,s.sid ,s.serial# ;
See the SQL behind the oracle processes:
select s.username
,s.sid ,s.serial#
,sql.sql_text
from v$session s, v$sqltext sql
where sql.address = s.sql_address
and sql.hash_value = s.sql_hash_value
--and upper(s.username) like 'USERNAME%'
order by s.username ,s.sid ,s.serial# ,sql.piece ;
To kill a troubled process:
alter system kill session 'SID,SERIAL#'; --substitute values for SID and SERIAL#
Identify a runaway Postgres query. First, logging must be enabled in the database. This imposes a performance penalty and should not be done in normal operation.
Edit the file postgresql.conf - its location depends on the PostGreSQL installation - and change
#stats_command_string = false
to
stats_command_string = true
Next, connect to postgres (psql service0 ) and select * from pg_stat_activity;. Typical output should look like:
datid | datname | procpid | usesysid | usename | current_query
----------+-------------+---------+----------+---------+-----------------
64344418 | openacs.org | 14122 | 101 | nsadmin | <IDLE>
64344418 | openacs.org | 14123 | 101 | nsadmin |
delete
from acs_mail_lite_queue
where message_id = '2478608';
64344418 | openacs.org | 14124 | 101 | nsadmin | <IDLE>
64344418 | openacs.org | 14137 | 101 | nsadmin | <IDLE>
64344418 | openacs.org | 14139 | 101 | nsadmin | <IDLE>
64344418 | openacs.org | 14309 | 101 | nsadmin | <IDLE>
64344418 | openacs.org | 14311 | 101 | nsadmin | <IDLE>
64344418 | openacs.org | 14549 | 101 | nsadmin | <IDLE>
(8 rows)
openacs.org=> The first task is to create an appropriate environment for finding out what is going on inside Oracle. Oracle provides Statspack, a package to monitor and save the state of the v$ performance views. These reports help finding severe problems by exposing summary data about the Oracle wait interface, executed queries. You'll find the installation instructions in $ORACLE_HOME/rdbms/admin/spdoc.txt. Follow the instructions carefully and take periodic snapshots, this way you'll be able to look at historical performance data.
Also turn on the timed_statistics in your init.ora file, so that Statspack reports (and all other Oracle reports) are timed, which makes them a lot more meaningful. The overhead of timing data is about 1% per Oracle Support information.
To be able to get a overview of how Oracle executes a particular query, install "autotrace". I usually follow the instructions here http://asktom.oracle.com/~tkyte/article1/autotrace.html.
The Oracle Cost Based optimizer is a piece of software that tries to find the "optimal" execution plan for a given SQL statement. For that it estimates the costs of running a SQL query in a particular way (by default up to 80.000 permutations are being tested in a Oracle 8i). To get an adequate cost estimate, the CBO needs to have adequate statistics. For that Oracle supplies the dbms_stats package.