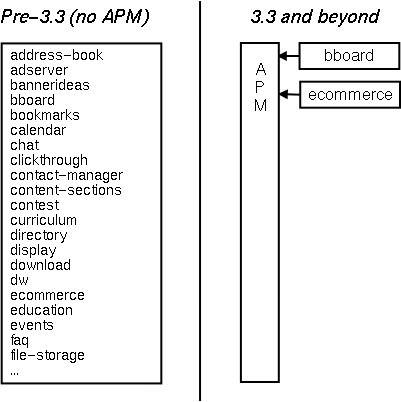
The APM is composed of systems for accomplishing a set of package-related tasks. Each of these tasks comprise a feature area that has an API, data model, and a UI:
-
Authoring a Package
-
Maintaining Multiple Versions of a Package
-
Creating Instances of the Package
-
Specifying Configuration Parameters for each Instance
Authoring a Package
Full instructions on how to prepare an OpenACS package are available in Packages. The API here can be invoked manually by a package's data model creation script, but need not to be used. This API is part of the APM PL/SQL package.
-- Informs the APM that this application is available for use.
procedure register_application (
package_key in apm_package_types.package_key%TYPE,
pretty_name in apm_package_types.pretty_name%TYPE,
pretty_plural in apm_package_types.pretty_plural%TYPE,
package_uri in apm_package_types.package_uri%TYPE,
singleton_p in apm_package_types.singleton_p%TYPE
default 'f',
spec_file_path in apm_package_types.spec_file_path%TYPE
default null,
spec_file_mtime in apm_package_types.spec_file_mtime%TYPE
default null
);
The procedure above registers an OpenACS application in the APM. It creates a new OpenACS object and stores information about the package, such as its name, in the APM data model. There is an analogous procedure for OpenACS services, called apm.register_service.
To remove an application from the system, there are the calls apm.unregister_application and apm.unregister_service.
-- Remove the application from the system.
procedure unregister_application (
package_key in apm_package_types.package_key%TYPE,
-- Delete all objects associated with this application.
cascade_p in char default 'f'
);
Use the cascade_p only if you want to completely remove the package from the OpenACS.
In order to determine if a particular package exists in the system, use the register_p predicate. It returns 1 if the specified package_key exists in the system, 0 otherwise.
function register_p (
package_key in apm_package_types.package_key%TYPE
) return integer;
Maintaining Multiple Versions of a Package
While the package authoring API provides a means for registering a package, some information about a package is version dependent. For example, between versions, the owner of a package, its vendor, its URI, and its dependency information may change. The API for package versions allows this information to be specified. All of these APIs are part of the apm_package_version PL/SQL package.
To create a new package version, use the apm_package_version.new constructor function.
function new (
version_id in apm_package_versions.version_id%TYPE
default null,
package_key in apm_package_versions.package_key%TYPE,
version_name in apm_package_versions.version_name%TYPE
default null,
version_uri in apm_package_versions.version_uri%TYPE,
summary in apm_package_versions.summary%TYPE,
description_format in apm_package_versions.description_format%TYPE,
description in apm_package_versions.description%TYPE,
release_date in apm_package_versions.release_date%TYPE,
vendor in apm_package_versions.vendor%TYPE,
vendor_uri in apm_package_versions.vendor_uri%TYPE,
installed_p in apm_package_versions.installed_p%TYPE
default 'f',
data_model_loaded_p in apm_package_versions.data_model_loaded_p%TYPE
default 'f'
) return apm_package_versions.version_id%TYPE;
In order to use this function, an existing package_key must be specified. The version_name parameter must follow a strict convention:
-
A major version number
-
at least one minor version number. Although any number of minor version numbers may be included, three minor version numbers is sufficient and is the convention of software developers.
-
One of the following:
-
The letter d, indicating a development-only version
-
The letter a, indicating an alpha release
-
The letter b, indicating a beta release
-
No letter at all, indicating a final production release
In addition, the letters d, a, and b may be followed by another integer, indicating a version within the release.
For those who like regular expressions:
version_number := ^[0-9]+((\.[0-9]+)+((d|a|b|)[0-9]?)?)$
So the following is a valid progression for version numbers:
0.9d, 0.9d1, 0.9a1, 0.9b1, 0.9b2, 0.9, 1.0, 1.0.1, 1.1b1, 1.1
To delete a given version of a package, use the apm_package_version.delete procedure:
procedure delete (
package_id in apm_packages.package_id%TYPE
);
After creating a version, it is possible to edit the information associated with it using apm_package_version.edit.
function edit (
new_version_id in apm_package_versions.version_id%TYPE
default null,
version_id in apm_package_versions.version_id%TYPE,
version_name in apm_package_versions.version_name%TYPE
default null,
version_uri in apm_package_versions.version_uri%TYPE,
summary in apm_package_versions.summary%TYPE,
description_format in apm_package_versions.description_format%TYPE,
description in apm_package_versions.description%TYPE,
release_date in apm_package_versions.release_date%TYPE,
vendor in apm_package_versions.vendor%TYPE,
vendor_uri in apm_package_versions.vendor_uri%TYPE,
installed_p in apm_package_versions.installed_p%TYPE
default 'f',
data_model_loaded_p in apm_package_versions.data_model_loaded_p%TYPE
default 'f'
) return apm_package_versions.version_id%TYPE;
Versions can be enabled or disabled. Enabling a version instructs APM to source the package's libraries on startup and to make the package available to the OpenACS.
procedure enable (
version_id in apm_package_versions.version_id%TYPE
);
procedure disable (
version_id in apm_package_versions.version_id%TYPE
);
Files associated with a version can be added and removed. The path is relative to the package-root which is acs-server-root/packages/package-key.
-- Add a file to the indicated version.
function add_file(
file_id in apm_package_files.file_id%TYPE
default null,
version_id in apm_package_versions.version_id%TYPE,
path in apm_package_files.path%TYPE,
file_type in apm_package_file_types.file_type_key%TYPE
) return apm_package_files.file_id%TYPE;
-- Remove a file from the indicated version.
procedure remove_file(
version_id in apm_package_versions.version_id%TYPE,
path in apm_package_files.path%TYPE
);
Package versions need to indicate that they provide interfaces for other software. An interface is an API that other packages can access and utilize. Interfaces are identified as a URI and a version name, that comply with the specification of a version name for package URIs.
-- Add an interface provided by this version.
function add_interface(
interface_id in apm_package_dependencies.dependency_id%TYPE
default null,
version_id in apm_package_versions.version_id%TYPE,
interface_uri in apm_package_dependencies.service_uri%TYPE,
interface_version in apm_package_dependencies.service_version%TYPE
) return apm_package_dependencies.dependency_id%TYPE;
procedure remove_interface(
interface_id in apm_package_dependencies.dependency_id%TYPE,
version_id in apm_package_versions.version_id%TYPE
);
procedure remove_interface(
interface_uri in apm_package_dependencies.service_uri%TYPE,
interface_version in apm_package_dependencies.service_version%TYPE,
version_id in apm_package_versions.version_id%TYPE
);
The primary use of interfaces is for other packages to specify required interfaces, known as dependencies. A package cannot be correctly installed unless all of its dependencies have been satisfied.
-- Add a requirement for this version. A requirement is some interface that this
-- version depends on.
function add_dependency(
requirement_id in apm_package_dependencies.dependency_id%TYPE
default null,
version_id in apm_package_versions.version_id%TYPE,
requirement_uri in apm_package_dependencies.service_uri%TYPE,
requirement_version in apm_package_dependencies.service_version%TYPE
) return apm_package_dependencies.dependency_id%TYPE;
procedure remove_dependency(
requirement_id in apm_package_dependencies.dependency_id%TYPE,
version_id in apm_package_versions.version_id%TYPE
);
procedure remove_dependency(
requirement_uri in apm_package_dependencies.service_uri%TYPE,
requirement_version in apm_package_dependencies.service_version%TYPE,
version_id in apm_package_versions.version_id%TYPE
);
As new versions of packages are created, it is necessary to compare their version names. These two functions assist in that task.
-- Given a version_name (e.g. 3.2a), return
-- something that can be lexicographically sorted.
function sortable_version_name (
version_name in apm_package_versions.version_name%TYPE
) return varchar;
-- Given two version names, return 1 if one > two, -1 if two > one, 0 otherwise.
-- Deprecate?
function compare(
version_name_one in apm_package_versions.version_name%TYPE,
version_name_two in apm_package_versions.version_name%TYPE
) return integer;
Creating Instances of a Package
Once a package is registered in the system, it is possible to create instances of it. Each instance can maintain its own content and parameters.
create or replace package apm_application
as
function new (
application_id in acs_objects.object_id%TYPE default null,
instance_name in apm_packages.instance_name%TYPE
default null,
package_key in apm_package_types.package_key%TYPE,
object_type in acs_objects.object_type%TYPE
default 'apm_application',
creation_date in acs_objects.creation_date%TYPE default sysdate,
creation_user in acs_objects.creation_user%TYPE default null,
creation_ip in acs_objects.creation_ip%TYPE default null,
context_id in acs_objects.context_id%TYPE default null
) return acs_objects.object_id%TYPE;
procedure delete (
application_id in acs_objects.object_id%TYPE
);
end apm_application;
Just creating a package instance is not sufficient for it to be served from the web server. A corresponding site node must be created for it. As an example, here is how the OpenACS API Documentation service makes itself available on the OpenACS main site:
declare
api_doc_id integer;
begin
api_doc_id := apm_service.new (
instance_name => 'OpenACS API Browser',
package_key => 'acs-api-browser',
context_id => main_site_id
);
apm_package.enable(api_doc_id);
api_doc_id := site_node.new (
parent_id => site_node.node_id('/'),
name => 'api-doc',
directory_p => 't',
pattern_p => 't',
object_id => api_doc_id
);
commit;
end;
/
show errors
Specifying Configuration Parameters for each Instance
A parameter is a setting that can be changed on a package instance basis. Parameters are registered on each package_key, and the values are associated with each instance. Parameters can have default values and can be of type 'string' or 'number.' There is support with this API for setting a number of minimum and maximum values for each parameter, but for most instances, the minimum and maximum should be 1. It is useful to allow or require multiple values for packages that need to store multiple pieces of information under one parameter. Default values are automatically set when instances are created, but can be changed for each instance.
All of the functions below are in the APM PL/SQL package.
-- Indicate to APM that a parameter is available to the system.
function register_parameter (
parameter_id in apm_parameters.parameter_id%TYPE
default null,
parameter_name in apm_parameters.parameter_name%TYPE,
description in apm_parameters.description%TYPE
default null,
package_key in apm_parameters.package_key%TYPE,
datatype in apm_parameters.datatype%TYPE
default 'string',
default_value in apm_parameters.default_value%TYPE
default null,
section_name in apm_parameters.section_name%TYPE
default null,
min_n_values in apm_parameters.min_n_values%TYPE
default 1,
max_n_values in apm_parameters.max_n_values%TYPE
default 1
) return apm_parameters.parameter_id%TYPE;
function update_parameter (
parameter_id in apm_parameters.parameter_id%TYPE,
parameter_name in apm_parameters.parameter_name%TYPE,
description in apm_parameters.description%TYPE
default null,
package_key in apm_parameters.package_key%TYPE,
datatype in apm_parameters.datatype%TYPE
default 'string',
default_value in apm_parameters.default_value%TYPE
default null,
section_name in apm_parameters.section_name%TYPE
default null,
min_n_values in apm_parameters.min_n_values%TYPE
default 1,
max_n_values in apm_parameters.max_n_values%TYPE
default 1
) return apm_parameters.parameter_name%TYPE;
-- Remove any uses of this parameter.
procedure unregister_parameter (
parameter_id in apm_parameters.parameter_id%TYPE
default null
);
The following functions are used to associate values with parameters and instances:
-- Return the value of this parameter for a specific package and parameter.
function get_value (
parameter_id in apm_parameter_values.parameter_id%TYPE,
package_id in apm_packages.package_id%TYPE
) return apm_parameter_values.attr_value%TYPE;
function get_value (
package_id in apm_packages.package_id%TYPE,
parameter_name in apm_parameters.parameter_name%TYPE
) return apm_parameter_values.attr_value%TYPE;
-- Sets a value for a parameter for a package instance.
procedure set_value (
parameter_id in apm_parameter_values.parameter_id%TYPE,
package_id in apm_packages.package_id%TYPE,
attr_value in apm_parameter_values.attr_value%TYPE
);
procedure set_value (
package_id in apm_packages.package_id%TYPE,
parameter_name in apm_parameters.parameter_name%TYPE,
attr_value in apm_parameter_values.attr_value%TYPE
);